文章内容
2017/8/22 9:35:45,作 者: 黄兵
python入门:爬虫抓取sina博客文章
python爬虫给我的感觉就是一个查找功能,网页用html来写的一个脚本,spider就是在这里面抓取你想要的信息。
这一章简单用爬虫实现抓取sina博客上的文章,并把它们的链接保存到本地(入门,没有用到ip代理、cookies、正则表达式等)。
准备材料:Google chrome浏览器、python27,spyder(IDE)
1.分析网页url
首先打开韩寒的新浪微博:http://blog.sina.com.cn/twocold
我们想要抓取的是博客中的文章,因此找到博文目录并点开:http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html
看到如下的界面: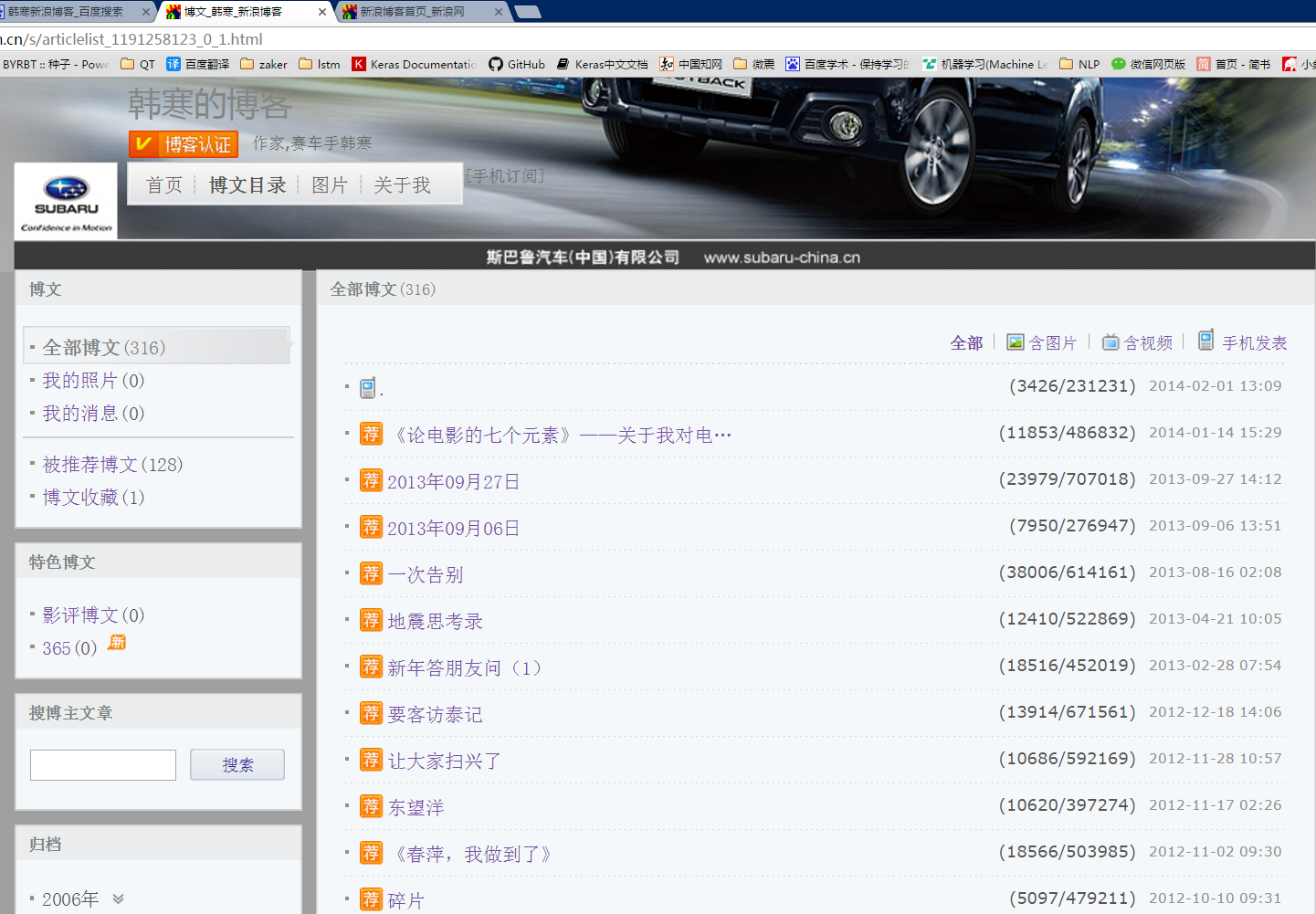
现在,点击鼠标右键--审查元素 或者直接按下F12,打开这张页面的html
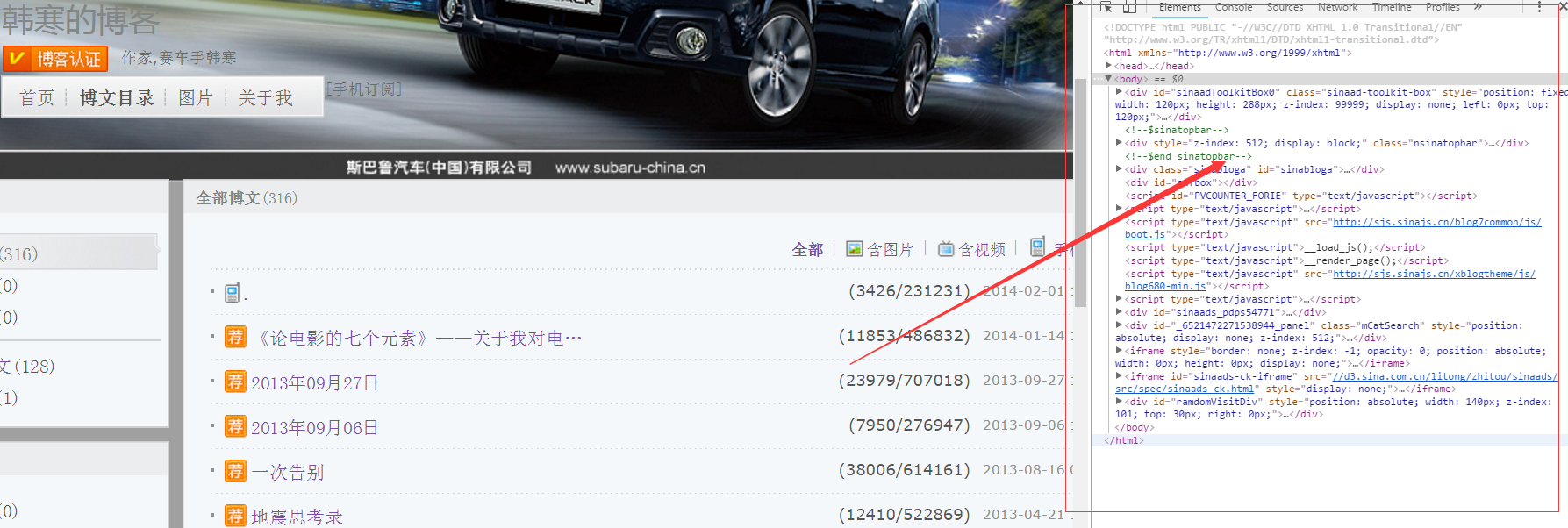
里面的内容很多,我们想要找到其中的文章title,比如第一篇《论电影的七个元素》,此时,通过ctrl+F打开查找器,输入‘论电影’,就可以找到它的位置啦~~
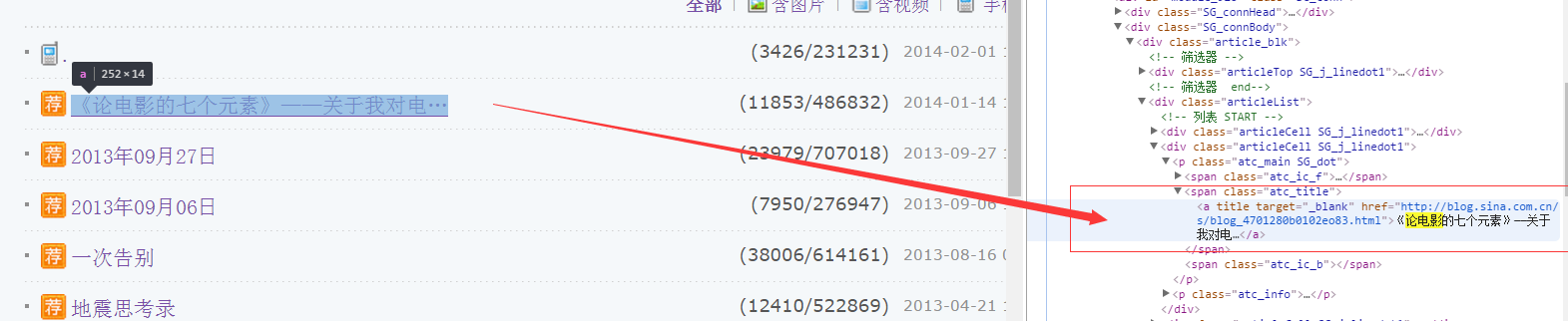
如上图,我们可以看到 a title 、href等关键字,后面的就是该篇文章对于的链接了(不信可以自己复制链接打开。。)。
2 .python代码条件设置
我们已经找到了一张html中的文章对应的位置,那么接下来就可以通过代码来实现了。
首先通过 import urllib加载urlopen的第三方库,
con=urllib.urlopen('http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html').read()
这一行的目的是通过python把该网页以html的形式读到python中(可以同print con来查看读取的内容,和在浏览器中用F12打开的内容一致)
设置一个判断条件,比如以一个开头和结尾作为提取文章对于链接的条件语句:
url.find是一个字符串查找函数,返回字符串第一个字符所在的索引,添加r表示为元字符,如果con中没有对于的字符串,那么该函数返回-1.
这时,我们已经找打了文章链接的在html中的索引,就可以把该文章对于的链接存放到一个list中,这里我用get_url=con[href+6:html+5]存放(此处加6和加5是因为find函数只返回字符串第一个字符所在的位置,需要再往后移动几位)。至此,我们已经把《论电影的七个元素》这篇文章的链接保存起来了,这时就需要保存到本地文件夹中,通过open函数保存:
open(r'blog_art/'+get_url[-26:],'w+').write(urllib.urlopen(get_url).read())
#这里表示打开文件夹‘blog_art’,‘w+’表示如果没有则新建,通过urlopen打开这个网站的html,并把其中文章对应的内容保存,对应的文件名为链接的后26个字符名字。
3.循环语句爬取整页文章
上面只是简单的爬取了第一页第一篇文章的内容保存到本地,可以看到第一页还有很多文章,我们这时通过循环语句来获取:
首先,还是通过url.find来实现,这个函数有一个功能就是它可以从指定位置开始查找,比如我上一次查找了A的位置,那么我第二次想查找B可以从A的位置开始查找。简单的说就是一张html中,文章按一定顺序排列的,我们找到了第一篇文章的索引位置,那么我们可以从这个索引往下找到第二篇文章:
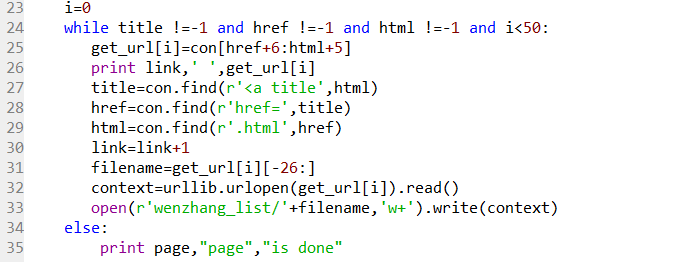
这里加了几个判断语句,就是title、href和html的查找不能为 空,这里i小于50是我大概看了韩寒老师的博客,一页大概50篇吧(大家自己数数~)。
4.循环遍历博客所有页面的文章
上面只是完成了对第一页文章的抓取,往后还有几页,这时可以通过分析每一页的链接的不同设置一个循环变量:
第一页:http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html
第二页:http://blog.sina.com.cn/s/articlelist_1191258123_0_2.html
第三页:http://blog.sina.com.cn/s/articlelist_1191258123_0_3.html
这三页链接已经可以看出了这个变量,这里我们设置一个int变量page来控制循环(int和str不能直接相加,要通过str(page)这个函数来完成):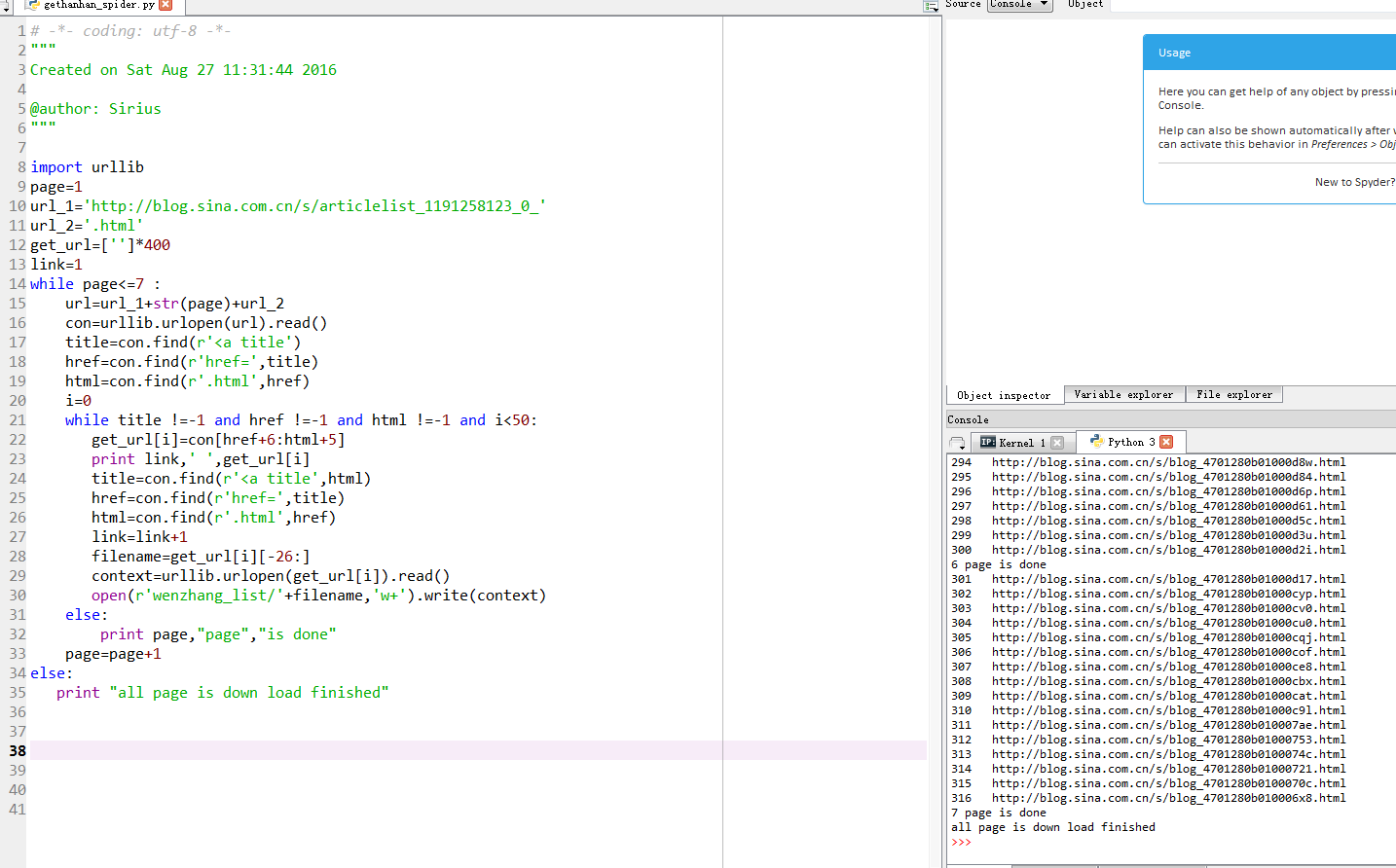
完整代码和运行结果,接下来让我们验证结果,打开***spider.py所在文件夹下的wenzhang_list这个文件夹看看结果:

这就是结果啦,打开看看: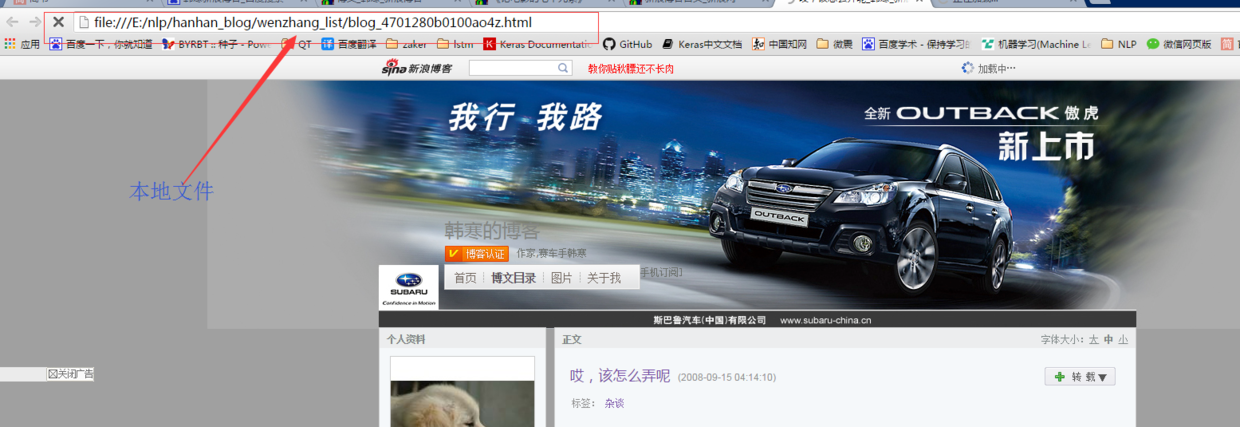
显示的是本地文件~~~~。
至此,本章的爬虫入门就讲完了,当然这都是很简单的,我们往往不想保存html这样的格式,比如做数据分析时往往想把爬取的数据存放到xls或者txt中,这就需要后期的正则表达式来进一步提取内容了;有些网站设置了障碍让你不能通过spider爬取内容,这时就需要用到agent。。。还有很多内容,哈哈慢慢来
作者:JRlu
链接:http://www.jianshu.com/p/e3bb88a75a7c
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
评论列表