文章内容
2019/4/17 16:59:15,作 者: 黄兵
MySQL查询优化
索引(在MySQL中也叫“键(key)”)是存储引擎用于快速找到记录的一种数据结构。这是索引的基本功能之一。
索引对于良好的性能非常关键。尤其是当表中的数据量越来越大时,索引对性能的影响愈发重要。在数据量较小且负载较低时,不恰当色索引对性能的影响可能还不明显,但数据量逐渐增大时,性能则会急剧下降。
不过,索引却经常被忽略,有时候甚至被误解。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易地将性能提高好几个数量级,“最优”的索引有时比一个“好的”索引性能要好几个数量级。创建一个真正“最优”的索引经常需要重写查询。
最近在线接收短信数据量增加很快,当时并没有很好的考虑到数据量增加会带来如此大的性能影响,现在数据量在140w左右,当翻到2w多页的时候,查询需要2s多,这对于网站来说简直是无法忍受。
必须要对数据库优化索引,原来索引已经无法满足性能要求了。
原来未经优化的查询:
SELECT * FROM table_name where xx=xx and a=a and c=c order by d desc limit 17280,10;
这个是原来的查询,一个查询需要2s左右,但是通过对xx,a,c列建立唯一索引,当然顺序也很重要,经过不断尝试,找出最优的索引顺序,关于这一点可以参考《高性能MySQL 第三版》[美]Baron Scbwartz,Peter Zaitsev,Vadim Tkacbenko著,第159页5.3.4节。
之后采用覆盖索引,来继续优化查询,具体查询实例:
SELECT * FROM table_name
INNER JOIN (SELECT id FROM table_name WHERE a = true AND b = 1 ORDER BY id DESC LIMIT 178240, 10)
AS x ON (x.id=table_name.id);关于覆盖索引可以参考《高性能MySQL 第三版》[美]Baron Scbwartz,Peter Zaitsev,Vadim Tkacbenko著,第171页5.3.6节。
虽然索引做好了,但是后端编码还需要修改,使用的是flask+SQLAlchemy(ORM)的方式,flask_sqlalchemy封装了一些东西,改动起来有些麻烦,但是经过不断查询资料,最终将这个问题解决。
原来查询分页的方式代码如下:
pagination = table_name.query.order_by(table_name.id.desc()) \
.filter(and_(table_name.IsShow == True, table_name.e == f)) \
.paginate(page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'], error_out=False)生成的sql没有经过任何优化,sql内容看上面第一个查询。
这里使用了一个flask_sqlalchemy的自动分页.paginate(),具体参考这里:flask_sqlalchemy.BaseQuery.paginate
但是使用封装好的分页方式,完全无法优化查询,必须要重写他的查询方式,之后参考stackoverflow,重写了分页查询的方式,具体代码如下:
page = request.args.get('page', 1, type=int)
# 选最剩余短信内容
c_query = db.session.query(table_name.id).order_by(table_name.id.desc()).filter(
and_(table_name.IsShow == True, table_name.e == f))
pagination = paginate(c_query, page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'], error_out=False)
surplus = pagination.items.paginate()具体实现方式:
def paginate(c_query, page, per_page, error_out):
if error_out and page < 1:
abort(404)
parent_items = c_query.limit(per_page).offset((page - 1) * per_page).subquery()
items = db.session.query(table_name).join(parent_items, table_name.id == parent_items.c.id).all()
if not items and page != 1 and error_out:
abort(404)
# No need to count if we're on the first page and there are fewer
# items than we expected.
if page == 1 and len(items) < per_page:
total = len(items)
else:
total = c_query.order_by(None).count()
return Pagination(c_query, page, per_page, total, items)这个翻页重写参考了stackoverflow的这篇文章:How to paginate in Flask-SQLAlchemy for db.session joined queries?
这里面用了子查询,关于子查询的相关资料参考这里:SQL Subquery 概念
还使用了SQLAlchemyde 连接查询,具体可以参考这篇文章:SQLAlchemy ORM教程之三:Relationship、SQLAlchemy —— 多表查询
如果在调试中需要查看SQLAlchemy生成的SQL语句,可以参考这篇文章:在 flask-sqlalchemy中,如何将查询语句转换成原始SQL打印出来?
具体看看sql是如何执行的:
EXPLAIN SELECT * FROM table_name
INNER JOIN (SELECT id FROM table_name WHERE a = true AND b = 1 ORDER BY id DESC LIMIT 178240, 10)
AS x ON (x.id=table_name.id);
通过这些优化以及重新修改分页的查询方式,将查询优化到了0.4s左右,140w的数据,有这个速度已经不错了。
在将来如果数据量达到了1000w级别,再怎么优化索引,也很难达到0.xs的速度,采用“分表”的方式,可能会解决这个问题,同时升级数据库的配置。
期待着这一天的到来。
陆陆续续搞了2天终于把这个问题解决了,以前一直要解决,一直没有下定决心去优化,但是这次借着服务器被DDOS的间隙,顺便优化查询,减轻数据库服务器的压力。
下面是优化前首字节加载时间:
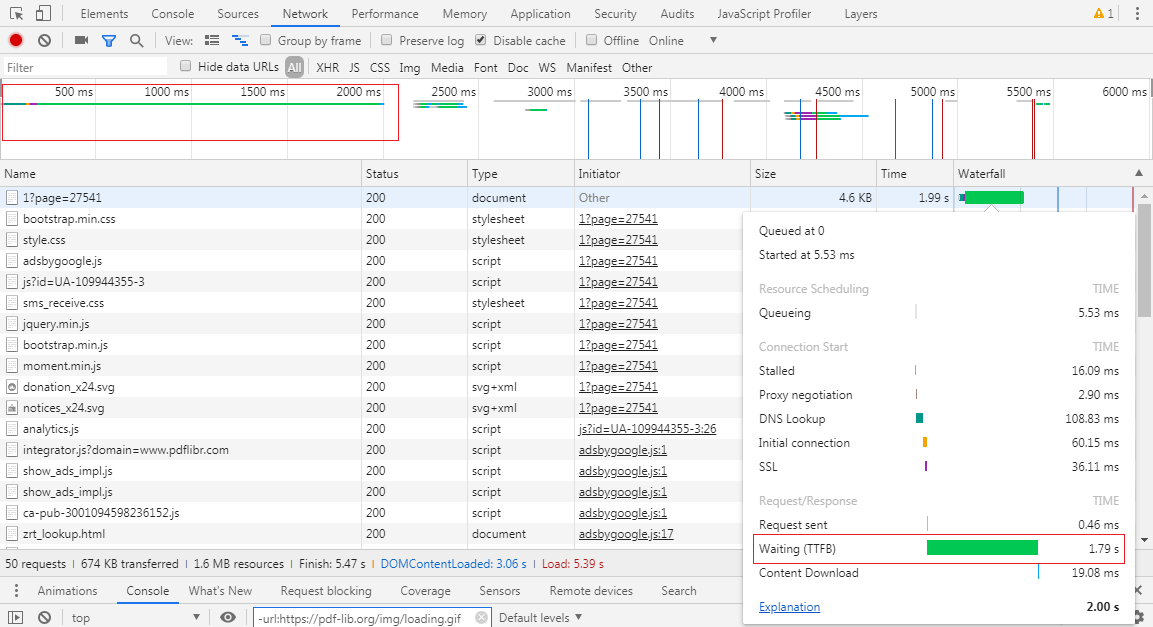
优化之后首字节加载时间:
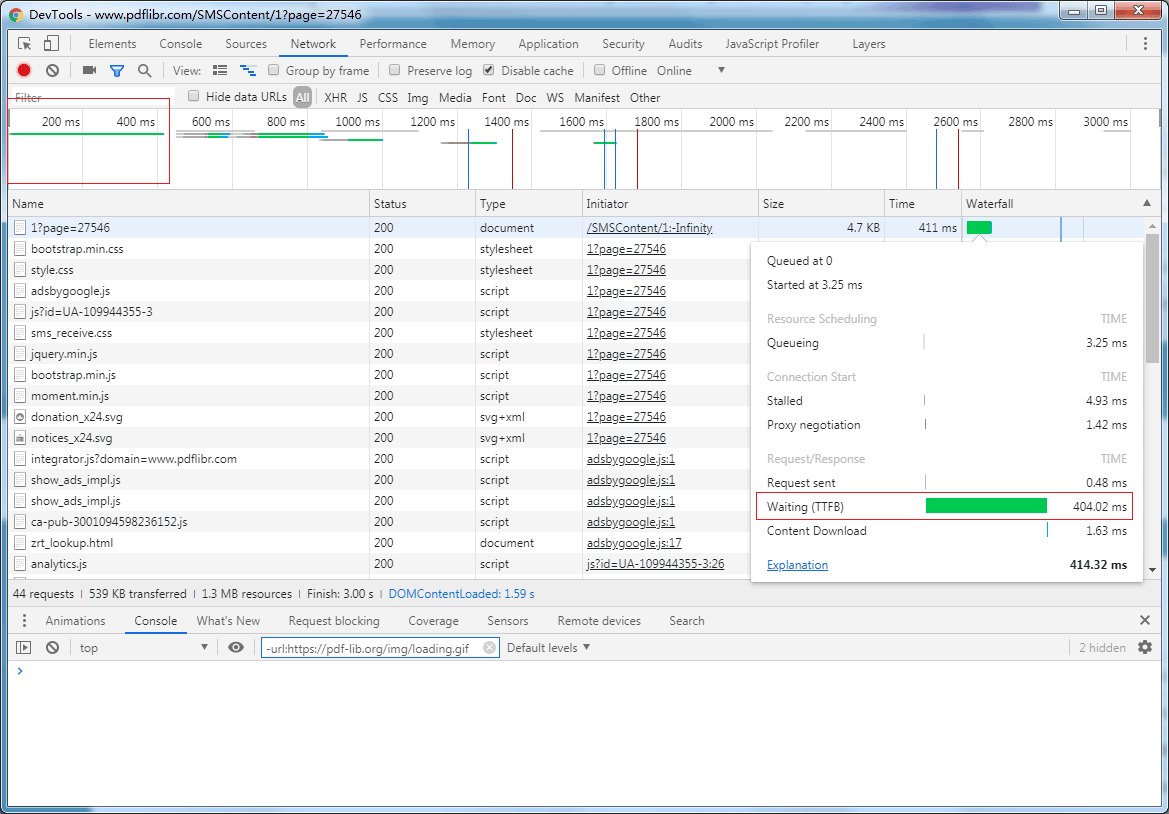
优化完成之后,又花了一上午完成了这篇文章,方便后来人。
由于这个项目是真实存在了,所以对于一些表结构进行了隐藏。
有问题欢迎留言。
参考资料:
1、《高性能MySQL 第三版》[美]Baron Scbwartz,Peter Zaitsev,Vadim Tkacbenko著
4、flask_sqlalchemy.BaseQuery.paginate
5、How to paginate in Flask-SQLAlchemy for db.session joined queries?
7、SQLAlchemy ORM教程之三:Relationship、SQLAlchemy —— 多表查询
8、在 flask-sqlalchemy中,如何将查询语句转换成原始SQL打印出来?
黄兵个人博客原创。
转载请注明出处:黄兵个人博客 - MySQL查询优化
Eric on 回复 有用(0)
你不像个程序员, 像个艺术家,优雅的艺术家!!
游客dtmc on 2019-05-28 10:03:53
博主回复:感谢您的肯定。