文章内容
2021/9/30 11:46:56,作 者: 黄兵
爬虫系列:爬虫所带来的道德风险与法律责任
使用网络爬虫做数据采集也应该有所不为。国内外关于网络数据保护的法律法规都在不断的制定与完善中,这篇文章主要从道德风险和法律责任两方面来分析爬虫做数据采集所带来的问题。
道德层面:
网络爬虫如果不严格控制网络采集的速度,会对被采集网站服务器造成很重的负担。恶意消耗别人网站的服务器资源,甚至是拖垮别人网站是一件不道德的事情。
我作为一个站长,也经常遭到爬虫的无节制抓取,下面分享我自己的案例:
在2018年11月5日左右,网站遭到了大量爬虫疯狂抓取,当天下午,服务器告警频发,首先是 CPU 100%,之后是网络跑满。
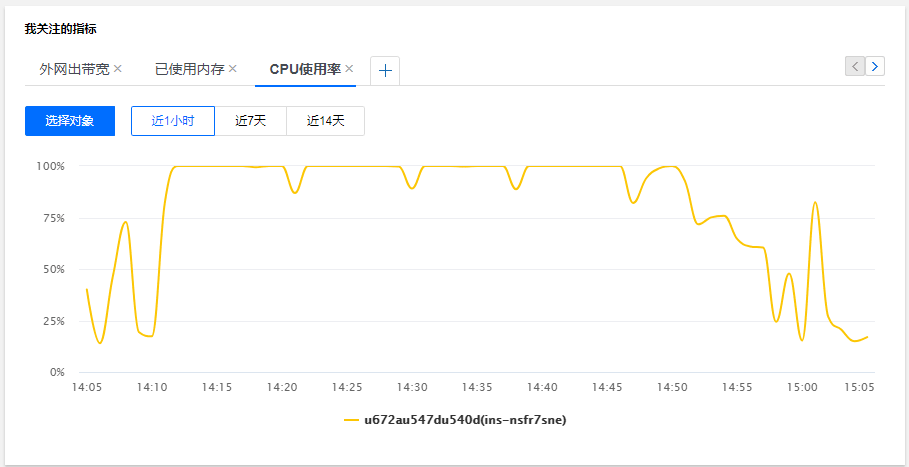
之后我对爬虫 IP 加入防火墙才最终将资源利用率降下来,14:50 之后可以看到资源利用率已经降下来了。
这里 CPU 利用率达到100%,用户访问网站的表现就是:访问速度非常缓慢,经常刷不出来。
这里是我作为一个站长分享自己被爬虫抓取的经历,希望爬虫开发者多站在别人的角度考虑问题。
上面说完了道德方面的问题,下面我们再来看看法律方面的责任。
法律层面:
涉嫌不正当竞争:
咪咕音乐公司以阿里音乐公司利用互联网爬虫技术实施“盗链”等不正当竞争方式侵害其合法权益为由提起诉讼
著作版权问题:
未经版权方确认,利用爬虫抓取版权方作品
非法收集公民个人信息:
非法获取公民个人信息
非法获取计算机信息系统数据:
侵入计算机信息系统,获取计算机系统内存储的大量数据
破坏计算机系统:
利用爬虫破坏计算机系统
以上整理了利用爬虫所触犯的法律法规,具体案例就不展开了,可以点击链接了解详细案情。
以上整理了爬虫可能触犯的法律,下面看看 robots.txt 协议对爬虫的约束:
从法理上来说,网站的服务协议和 robots.txt 是很有趣的。如果一个网站允许公众访问接入,那么网站管理员对软件可以接入什么和不可以接入什么的限制是不合理的。如果网站管理员对“你用浏览器访问没有问题,但是你用自己写的程序访问它就不行”,这就不太靠谱了。
如果你了解搜索引擎优化(SEO)或搜索引擎技术,那么你可能听说过 robots.txt 文件。如果你想在任何大型网站上找到 robots.txt 文件,可以在网站根目录 https://www.pdflibr.com/robots.txt 找到。
robots.txt 文件是在 1994 年出现的,那时搜索引擎技术刚刚兴起。从整个互联网寻找资源的搜索引擎, 像 Alta Vista 和 DogPile,开始和那些把网站按照主题进行分类的门户网站公司竞争激烈,比如像 Yahoo! 这样的门户网站。互联网搜索规模的增长不仅说明网络爬虫数量的增长,而且也体现了网络爬虫搜集信息的能力在不断变化。
虽然我们今天认为这种能力是十分平常的,但是当自己网站文件机构深处隐藏的信息变成搜索引引擎首页上可以检索的内容时,有些管理员还是非常震惊。于是,robots.txt 文件,也被称为机器人排除标准(Robots Exclusion Standard),应运而生。
robots.txt 的语法没有标准格式。他是一种业内惯用的做法,但是没有人可以阻止别人创建自己版本的 robots.txt 文件(并不是说如果它不符合主流标准,机器人就可以不遵守)。它是一种被企业广泛认可的习惯,主要是这么做很直接,而且企业也没有动力去发展自己的版本,或者去尝试去改进它。
robots.txt 文件并不是一个强制性约束。他只是说“请不要抓取网站这些内容”。有很多网络爬虫库都支持 robots.txt 文件(虽然这些默认设置很容易修改)。另外,按照 robots.txt 文件采集信息比直接采集信息麻烦得多(毕竟,你需要采集、分析,并在代码逻辑中处理页面内容)。
机器人排除标准得语法很直接。和 Python 语言一样,注释都是用 # 号,用换行结尾,可以用在文件的任意位置。
文件第一行非注释内容是 User-agent:,注明具体那些机器人需要遵守规则。后面是一组 Allow: 或 Disallow:,决定是否允许机器人访问网站该部分内容。星号(*)是通配符,可以用于 User-agent:,也可以用于 URL 链接中。
如果一条规则后面跟着一个与之矛盾的规则,则按照后一条规则执行。例如:
# Welcome to me robots.txt file!
User-agent: *
Disallow: *
User-Agent: Googlebot
Allow: *
Disallow: /private
在这个例子中,所有机器人都被禁止访问任何内容,除了 Google 的网络机器人,他被允许访问网站上除了 /private 位置的所有内容。
是否按照 robots.txt 文件的要求写网络爬虫是由你自己决定的,当爬虫毫无节制地采集网站的时候,强烈建议你遵守。
文章来源:爬虫系列:爬虫所带来的道德风险与法律责任
评论列表