文章内容
2021/1/5 18:03:00,作 者: 黄兵
关于使用文件作为存储处理结果的一些思考
最近在使用python写程序,主要是将ASN的数据写入到数据库,数据非常的多,有45w行左右,截图如下:
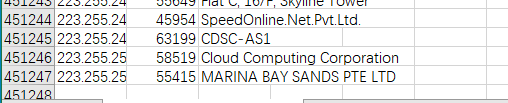
读取之后,将结果保存到数据库,但是由于数据量太大,中间可能存在中断,所以需要将已经保存到记录放在另外一个文件。
每次读取的时候,检查当前记录是否在已处理文件里面,具体代码如下:
asn_file_path = os.path.join(os.getcwd(), 'files\\IPv4.csv')
init_redis = redis_config.ConnConfig().Conn_Redis()
if os.path.exists(asn_file_path):
with open(asn_file_path, 'r') as csv_file:
# 读取csv文件
csv_reader = csv.reader(csv_file)
# 读取第一行
next(csv_reader)
for row in csv_reader:
processed_data = self.read_processed_data()
if row in processed_data:
# csv文件当前行已经被处理过,继续循环
continue
逻辑应该是没有问题。
但是当多程序运行的时候,会出现问题。当多线程运行的时候,第一个线程读取之后,第二个线程读取,结果第一个线程还没有写入,第二个读取到同一列数据,导致数据重复。
通过记录处理完成的csv文件可以查证:
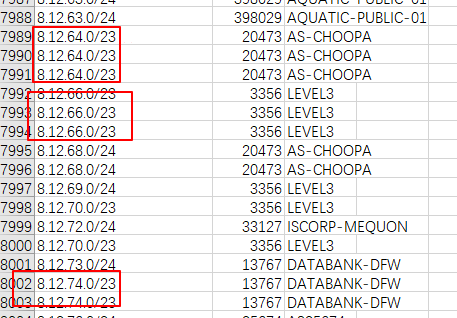
这些都是重复数据,说明在程序设计的时候存在问题。
出现这个问题的解决方案:
可以将这些数据保存到数据库,读取一条删除一条,或者是保存到Redis,同样也是读取一条删除一条。
我这里采用的是后面一种方式。
有任何好的建议,欢迎大家讨论。
黄兵个人博客原创。
转载请注明出处:黄兵个人博客 - 关于使用文件作为存储处理结果的一些思考
评论列表