文章内容
2020/9/10 15:41:31,作 者: 黄兵
MySQL查询大量数据所面临的一些问题
最近需要将历史数据保存到其他表,也就是俗称的分表,但是光是一年的数据就有1000w左右,查询出来用了10多分钟,之后开始遍历字段,遍历每个字段都需要非常长的时间,具体代码如下:
get_all = cur.fetchall()
for item in get_all:
sms_receive_id = item[0]
phone_number = item[1]
content = item[2]
receive_time = item[3]
is_type = item[4]
show = item[5]
phone_number_id = item[6]查询出来的结果数据,如下图所示:
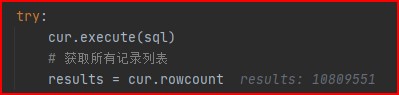
总共有1080万条数据,看看遍历用了多少内存:
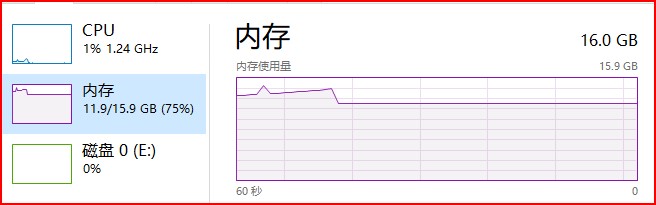
平常最多使用到40%的内存,现在已经使用了75%的内存,也就是16G的内存,光这个查询使用了16*(75%-45%)=5.6G的内存,这只是在本地,如果在远程服务器,这个花费就不菲,必定6G内存的服务器可不便宜。
这里只是给大家展示大量数据查询所带来的问题,不仅耗时,同时对计算机资源也是一个非常大的消耗。
用分页可以避免这个问题,在MySQL查询大量数据分页文章中我们来详细讨论大型查询如何做分页查询。
黄兵个人博客原创。
转载请注明出处:黄兵个人博客 - MySQL查询大量数据所面临的一些问题
a1sd on 回复 有用(0)
继续加油啊博主!相信自己