文章内容
2017/9/12 9:38:14,作 者: 黄兵
抓取新浪博客内容
抓取新浪文章列表内容:
import urllib
import lxml.html
import csv
import codecs
import sys
reload(sys)
sys.setdefaultencoding('utf8')
con=urllib.urlopen('http://blog.sina.com.cn/s/articlelist_5971014532_0_1.html').read()
tree=lxml.html.fromstring(con)
fixed_html=lxml.html.tostring(tree,pretty_print=True)
for i in range(1,50):
title=tree.cssselect('.atc_title > a')[i].get('href')
rows=[]
rows.append(title)
for i in rows:
html_rows=urllib.urlopen(i).read()
tree_rows=lxml.html.fromstring(html_rows)
title_rows=tree_rows.cssselect('.articalTitle .titName.SG_txta')[0].text_content()
body_rows=tree_rows.cssselect('.artical .articalContent.newfont_family')[0].text_content()
context_rows=[]
context_rows.append([title_rows.encode('utf-8'),body_rows.encode('utf-8')])
print context_rows
with open('sina_context.csv','wb') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
writers = csv.writer(csvfile)
csvfile.write(codecs.BOM_UTF8)
spamwriter.writerow(context_rows)
转码还有些问题,需要修复。
进过半个小时的修复终于可以实现翻页,抓取每一页的具体文章内容,代码如下:
import urllib
import lxml.html
import csv
import codecs
import sys
reload(sys)
sys.setdefaultencoding('utf8')
for page in range(1,31):
print 'http://blog.sina.com.cn/s/articlelist_5971014532_0_{0}.html'.format(page)
con = urllib.urlopen('http://blog.sina.com.cn/s/articlelist_5971014532_0_{0}.html'.format(page)).read()
tree=lxml.html.fromstring(con)
fixed_html=lxml.html.tostring(tree,pretty_print=True)
for i in range(1,50):
title=tree.cssselect('.atc_title > a')[i].get('href')
rows=[]
rows.append(title)
for i in rows:
html_rows=urllib.urlopen(i).read()
tree_rows=lxml.html.fromstring(html_rows)
title_rows=tree_rows.cssselect('.articalTitle .titName.SG_txta')[0].text_content()
body_rows=tree_rows.cssselect('.artical .articalContent.newfont_family')[0].text_content()
context_rows=[]
context_rows.append([title_rows,body_rows])
print context_rows
with open('sina_context.csv','a') as csvfile:
spamwriter = csv.writer(csvfile)
writers = csv.writer(csvfile)
csvfile.write(codecs.BOM_UTF8)
for rows_text in context_rows:
spamwriter.writerow(rows_text)
最后抓取的文件是保存在csv文件中,截图如下:
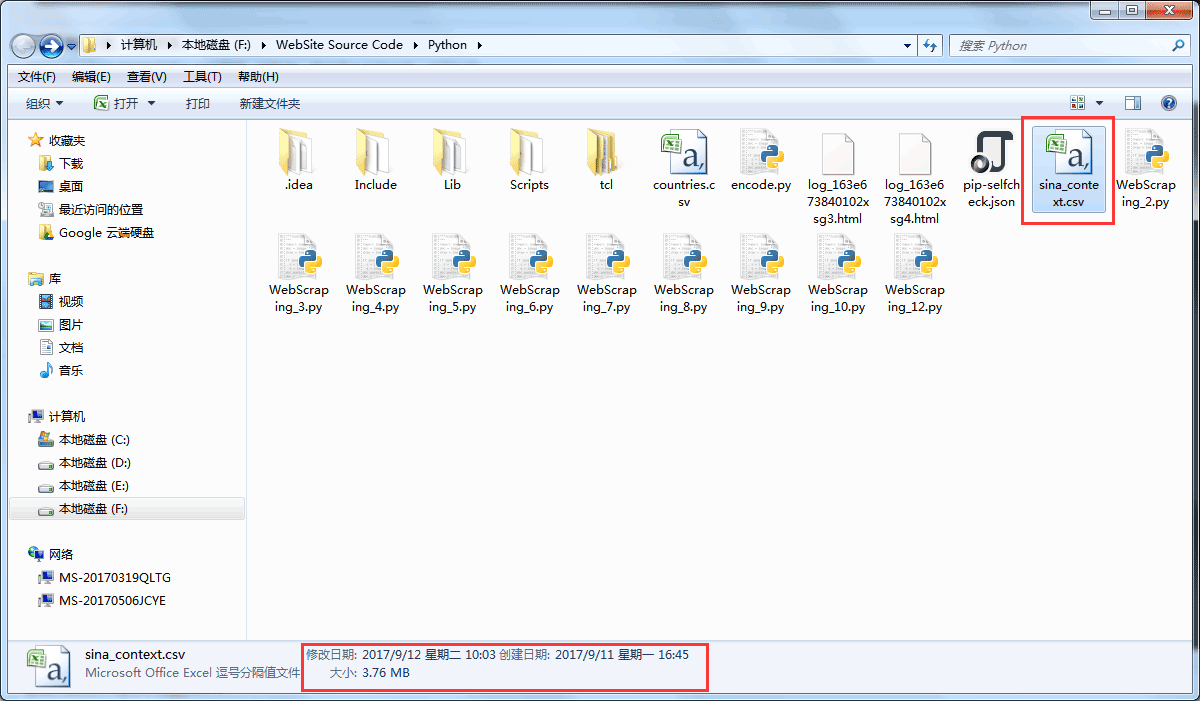
可以看到文件还是比较大的,打开十分慢。
本来编码有各种各样的问题,后来在网上找了一下资料,终于把问题解决了。保存的csv文件也没有乱码。

黄兵个人博客原创。
转载请注明出处:黄兵个人博客 - 爬虫 抓取新浪博客
lxml.etree._ElementUnicodeResult 转为字符
TinyOS生成docs时报UnicodeDecodeError: 'ascii' codec can't decode byte错误的解决方法
TinyOS生成docs时报UnicodeDecodeError: 'ascii' codec can't decode byte错误的解决方法
评论列表