文章内容
2017/8/20 18:17:21,作 者: 黄兵
Python爬虫日记三:爬取v2ex数据用csv保存
一:前言
v2ex是一个汇集各类奇妙好玩的话题和流行动向的网站,有很多不错的问答。这次爬虫是五一期间做的,贴出来网址https://www.v2ex.com/?tab=all。
目标:爬取全部分类中的文章标题,分类,作者,文章地址这些内容然后以csv格式保存下来。
二:说明
- 本次使用的是Python3.6版本
- 作者这个内容是js动态数据 使用xpath Beautifulsoup的tag和select都抓取不到,我试了试用正则表达式可以,目前还没学其他方法就这样头铁了。
- 使用csv保存数据的时候我发现writer.writerow()和writer.writerows()是不一样的,本次用的前者。
三:实战分析
1.导入本次使用的模块,csv, re, requests, BeautifulSoup。
import csv, requests, re
from bs4 import BeautifulSoup2.请求网页与解析网页。
url = 'https://www.v2ex.com/?tab=all'
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')3.先看一下网页结构。
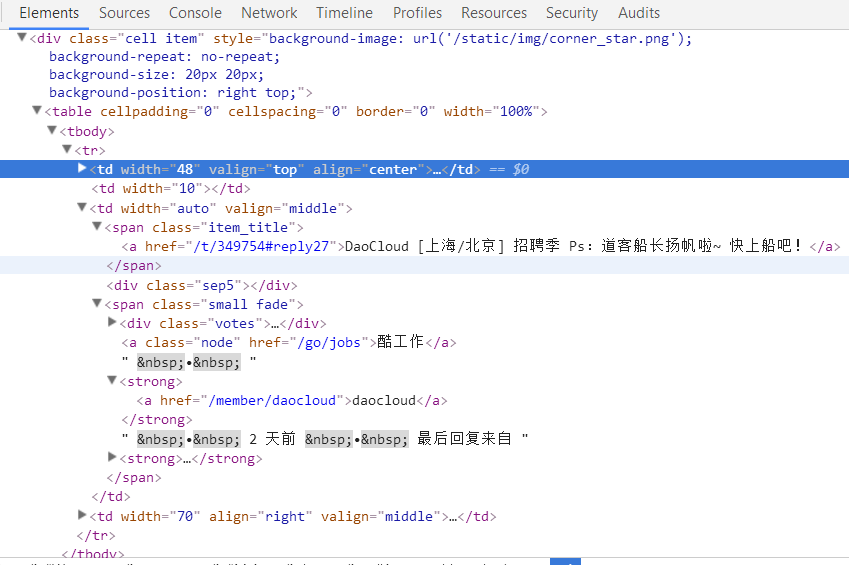
然后来获取文章标题,分类,作者,文章地址,这里的标题和分类都很容易获取,使用BeautifulSoup解析后按照class就可以找到,然后使用get_text()即可获取我们需要的内容,最头疼的是作者和文章链接,我这里使用正则才把他们挖掘出来,不过也算是练习正则表达式的使用。最后把获取的内容都传给articles列表。
articles = []
for article in soup.find_all(class_='cell item'):
title = article.find(class_='item_title').get_text()
category = article.find(class_='node').get_text()
author = re.findall(r'(?<=<a href="/member/).+(?="><img)', str(article))[0]
u = article.select('.item_title > a')
link = 'https://www.v2ex.com' + re.findall(r'(?<=href=").+(?=")', str(u))[0]
articles.append([title, category, author, link])4.把列表中的数据保存在csv中,并且给他们第一行写入标题。
with open('v2ex.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['文章标题', '分类', '作者', '文章地址'])
for row in articles:
writer.writerow(row)四:总结
最后的效果:
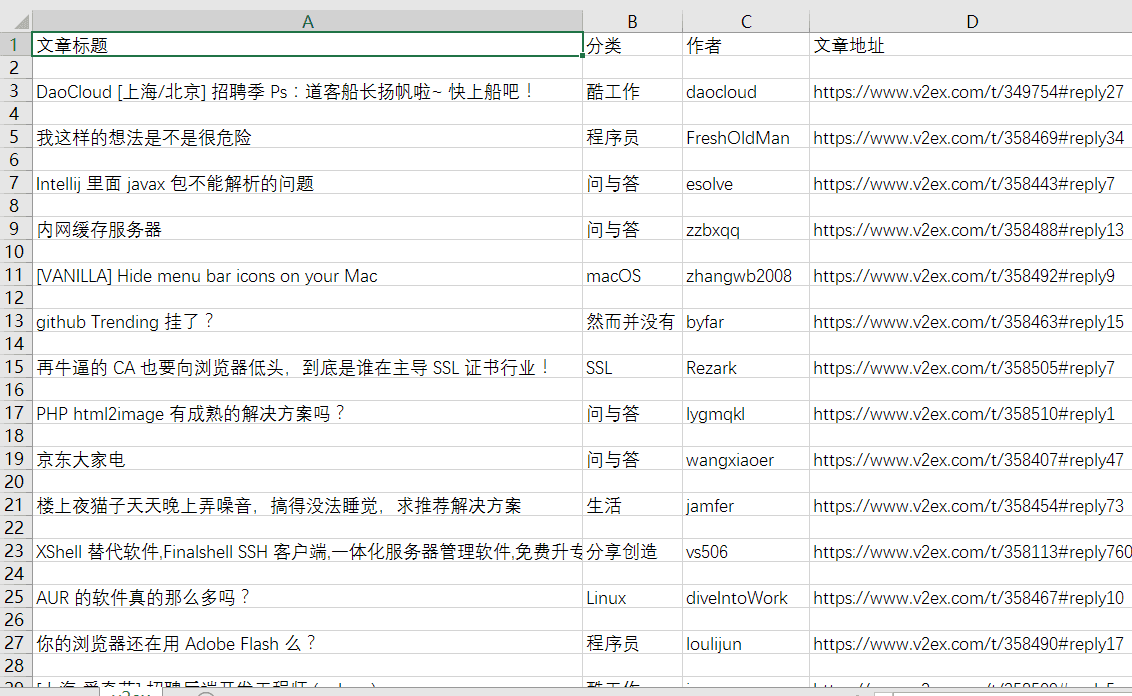
这次爬取遇到了一些问题,慢慢的学会更多东西,爬虫让我非常快乐。我以后会坚持写下去,有喜欢的朋友一起学习交流吧!
这里贴出我的github地址,我的爬虫代码和学习的基础部分都放进去了。
https://github.com/rieuse/learnPython
作者:布咯咯_rieuse
链接:http://www.jianshu.com/p/d1bf2f0bdc51
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
评论列表