文章内容
2017/12/26 16:59:29,作 者: 黄兵
Python获取图片地址
最近在使用Python写爬虫,文章中的很多图片需要下载到本地,就需要获取图片地址,一下采用第三方获取图片地址:
使用BeautifulSoup库代码如下:
- #coding=utf-8
- import urllib2
- from bs4 import BeautifulSoup
- def getImg(url):
- html = urllib2.urlopen(url)
- page = html.read()
- soup = BeautifulSoup(page, "html.parser")
- imglist = soup.find_all('img')
- #发现html中带img标签的数据,输出格式为<img xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx,存入集合
- lenth = len(imglist) #计算集合的个数
- for i in range(lenth):
- print imglist[i].attrs['src']
- #抓取img中属性为src的信息,例如<img src="123456" xxxxxxxxxxxxxxxx,则输出为123456
- url = 'http://tieba.baidu.com/p/4161148236?fr=frs'
- getImg(url)
使用Lxml.html库代码如下:
import urllib
import lxml.html
import csv
import codecs
import sys
import requests
import json
import requests.packages.urllib3.util.ssl_
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS = 'ALL'
reload(sys)
sys.setdefaultencoding('utf8')
for page in range(1,63):
res = requests.get('http://pdf-lib.org/api/zhihu?CurrentPage={0}&PageSize={1}'.format(page,8)).text
parsed_json=json.loads(res)
jsonResult= parsed_json['results']
for item in jsonResult:
BlogId = item['Blog_Id']
contextUrl=requests.get('https://pdf-lib.org/Tools/ZhihuDaily/Story/{0}'.format(BlogId)).text
tree = lxml.html.fromstring(contextUrl)
fixed_html = lxml.html.tostring(tree, pretty_print=True)
length=len(tree.cssselect('.content-image'))
for i in range(length):
imgsrc=tree.cssselect('.content-image')[i].get('src')
print imgsrc
通过BeautifulSoup库获取图片地址没有测试,在此就不截图了。
通过Lxml.html获取图片地址截图如下:
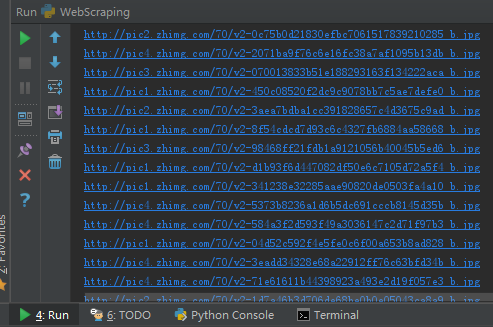
参考资料: Python之BeautifulSoup学习之一 粗略抓取网页图片连接地址
黄兵个人博客原创。
评论列表