文章内容
2022/4/18 18:59:25,作 者: 黄兵
How crawler data is collected and organized
Some users have been curious about how the crawler data on the crawler-aware website is organized, and today we will be more than curious to reveal how the crawler data is collected and organized.
The way to get rDNS by querying IP address
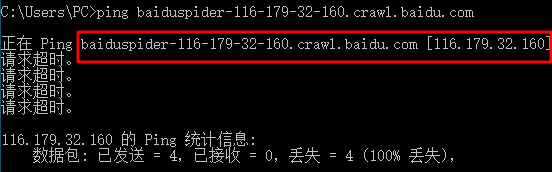
We can reverse the IP address of the crawler to query the rDNS, for example: we find this IP: 116.179.32.160, rDNS by reverse DNS lookup tool: baiduspider-116-179-32-160.crawl.baidu.com
From the above, we can roughly determine should be Baidu search engine spiders. Because Hostname can be forged, so we only reverse lookup, still not accurate. We also need to forward lookup, we ping command to find baiduspider-116-179-32-160.crawl.baidu.com can be resolved as: 116.179.32.160, through the following chart can be seen baiduspider-116-179-32-160.crawl. baidu.com is resolved to the IP address 116.179.32.160, which means that the Baidu search engine crawler is sure.
Searching by ASN-related information
Not all crawlers follow the above rules, most crawlers reverse lookup without any results, we need to query the IP address ASN information to determine if the crawler information is correct.
For example, this IP is 74.119.118.20, we can see that this IP address is the IP address of Sunnyvale, California, USA by querying the IP information.
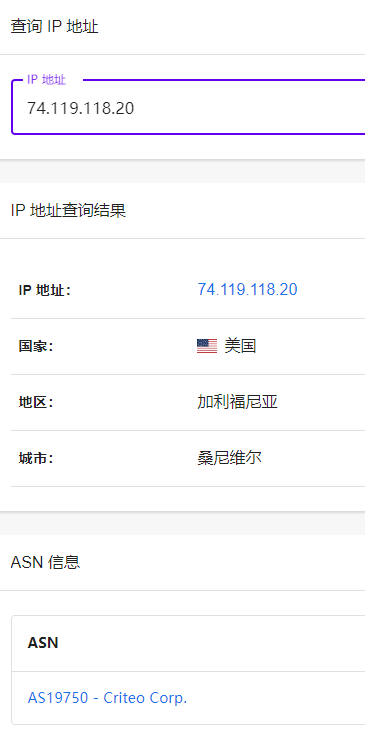
We can see by the ASN information that he is an IP of Criteo Corp.
The screenshot above shows the logging information of critieo crawler, the yellow part is its User-agent, followed by its IP, and there is nothing wrong with this entry (the IP is indeed the IP address of CriteoBot).
IP address segment published by the crawler's official documentation
Some crawlers publish IP address segments, and we save the officially published IP address segments of the crawler directly to the database, which is an easy and fast way to do this.
Through public logs
We can often view public logs on the Internet, for example, the following image is a public log record I found.
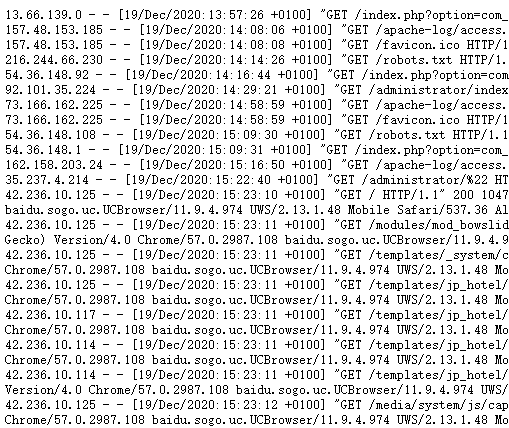
We can parse the log records to determine which are crawlers and which are visitors based on the User-agent, which greatly enriches our database of crawler records.
Summary
The above four methods detail how the crawler identification website collects and organizes crawler data, and how to ensure the accuracy and reliability of the crawler data, but of course there are not only the above four methods in the actual operation process, but they are less used, so they are not introduced here.
Warning: the ECDSA host key for '[]:22' differs from the key for the IP address
评论列表