文章内容
2017/9/22 11:08:51,作 者: 黄兵
字典和集合
1 字典:当索引不好用时
字典是我们小学的时候学习汉字最有利的助手,可以通过拼音或者偏旁可以更方便准确的查找你要找的字并根据字找到字的含义。但是在Python中也有字典,不过Python的字典把字(或单词)称为“键(key)”,其对应的含义称为“值(value)”。Python的字典有些地方称为哈希(hash),有些地方称为关系数组。
字典是Python中唯一的映射类型,映射是数学上的一个术语,是指两个元素集之间元素相互“对应”的关系。
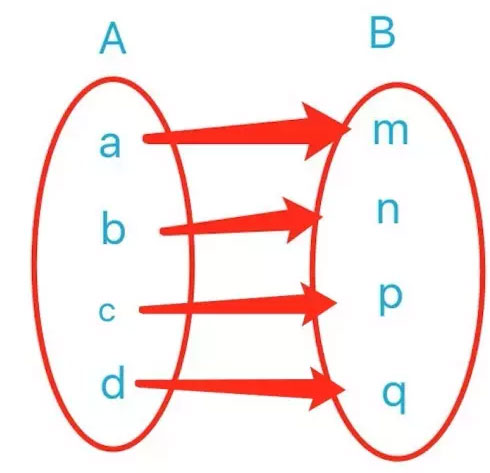
映射类型区别于序列类型,序列类型以数组的形式存储,通过索引的方式来获取相应位置的值,一般索引值与对应位置存储的数据是毫无关系的,举个例子:
>>> brand = ['wolf','Python3v','Hello']
>>> slogan = ['一切皆有可能','Just do it', 'Yes I can','让编程改变世界']
>>> print('python3v的口号是:', slogan[brand.index('Hello')])
python3v的口号是: Yes I can
这里用到了列表的index()方法获取元素的索引,原本列表brand,slogan的索引和值是没有关系的,唯一有关系的是两个列表的索引号,利用index()方法找到slogan对应的索引口号,间接的实现利用brand找到slogan的元素。因为Python是以简洁为主,所以需要字典这种映射类型的出现。
1.1 创建和访问字典
先举个例子:
>>> dict1 = {'Python':'Python3v','Linux':'Centos7','Ruby':'Ruby3','Go':'Go跑的快'}
>>> dict1
{'Python': 'Python3v', 'Linux': 'Centos7', 'Ruby': 'Ruby3', 'Go': 'Go跑的快'}
字典的使用也是很简单的,也有自己的标志符号就是大括号({})定义。字典有多个键及对应的值共同构成。每一对键值组合称为项,在dist1字典中,‘Python’、‘Linux’、‘Ruby’、‘Go’就是字典的键,而‘Python3v’、‘Centos7’、‘Ruby’、‘Go跑的快’就是对应键的值。字典中的项跟创建的顺序是不一样的,字典跟序列不同,序列讲究的是顺序,而字典讲究的是映射,不讲顺序。
注:字典的键必须是独一无二在一个字典中,而值可以取任何数据类型,但必须是不可变的(如字符串,数或元组。)
如果创建一个空字典,只需要一个大括号即可:
>>> dict1 = {}
>>> dict1
{}
>>> type(dict1)
<class 'dict'>
也可以用dict()来创建字典:
>>> dict1=dict((('A',65),('F',70),('Q',81),('S',83)))
>>> dict1
{'A': 65, 'F': 70, 'S': 83, 'Q': 81}
因为dict()函数的参数可以是一个序列(但是不能是多个),所以要打包成一个元组序列( 列表可以)。不过也可以通过映射关系的参数来创建字典:
>>> dict1=dict(A=65,F=70,Q=81,S=83)
>>> dict1
{'F': 70, 'A': 65, 'S': 83, 'Q': 81}
注:如果通过映射关系创建的字典,键的位置不能加上字符串的引号,否则会报错。
还有一种创建字典的方法就是直接给字典的键赋值,如果键存在,则改写键对应的值,如果不存在,则创建一个新的键并赋值:
>>> dict1
{'F': 70, 'A': 65, 'S': 83, 'Q': 81}
>>> dict1['B'] = 66
>>> dict1
{'F': 70, 'A': 65, 'S': 83, 'Q': 81, 'B': 66}
>>> dict1['A'] = 66
>>> dict1
{'F': 70, 'A': 66, 'S': 83, 'Q': 81, 'B': 66}
>>> dict1['Q'] = 66
>>> dict1
{'F': 70, 'A': 66, 'S': 83, 'Q': 66, 'B': 66}
以上五种方法都是创建字典的方法,可以看看下面这个:
>>> a = dict(one=1,two=2,three=3)
>>> b = {'one':1,'two':2,'three':3}
>>> c = dict(zip(['one','two','three'],[1,2,3]))
>>> d = dict({'one':1,'two':2,'three':3})
>>> e = dict([('one',1),('two',2),('three',3)])
>>> a == b == c == d == e
True
1.2 各种内置方法
字典是Python中唯一的映射类型,不是序列。在序列中为一个不存在的位置赋值会报错,而字典会自动创建相对应的键并添加对应的值进去。
1.2.1 fromkeys()
fromkeys()方法用于创建并返回一个新字典,它有两个参数:第一个参数是字典的键,第二个参数是可选的,是传入键对应的值,如果不加就是None,举个例子:
>>> dict1= {}
>>> dict1.fromkeys((1,2,3))
{1: None, 2: None, 3: None}
>>> dict2 = {}
>>> dict2.fromkeys((1,2,3),"Python3v")
{1: 'Python3v', 2: 'Python3v', 3: 'Python3v'}
>>> dict3 = {}
>>> dict3.fromkeys((1,2,3),('one','two','three'))
{1: ('one', 'two', 'three'), 2: ('one', 'two', 'three'), 3: ('one', 'two', 'three')}
fromkeys()方法并不会把后面的元组分别赋值键1,2,3上,因为fromkeys()把后面的元组当成一个值啦。
1.2.2 keys()、values()和items()
字典的访问方法有keys()、values()和items()
keys()用于返回字典中的键,values()用于返回字典中所有的值,items()就是返回的所有的键值对(也就是所有的项啦)。看一下例子:
>>> dict1 = {}
>>> dict1 = dict1.fromkeys(range(32),'赞')
>>> dict1.keys()
dict_keys([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31])
>>> dict1.values()
dict_values(['赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞', '赞'])
>>> dict1.items()
dict_items([(0, '赞'), (1, '赞'), (2, '赞'), (3, '赞'), (4, '赞'), (5, '赞'), (6, '赞'), (7, '赞'), (8, '赞'), (9, '赞'), (10, '赞'), (11, '赞'), (12, '赞'), (13, '赞'), (14, '赞'), (15, '赞'), (16, '赞'), (17, '赞'), (18, '赞'), (19, '赞'), (20, '赞'), (21, '赞'), (22, '赞'), (23, '赞'), (24, '赞'), (25, '赞'), (26, '赞'), (27, '赞'), (28, '赞'), (29, '赞'), (30, '赞'), (31, '赞')])
如果字典中的项不存在字典中,Python就会报错:
>>> print(dict1[32])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 32
在调试代码的时候,报错会用程序员及时发现问题的所在并修改,但是如果程序面向用户出现错误就会被遗弃。。。。
1.2.3 get()
get()方法是访问字典项,如果字典中不存在键的时候,get()方法会返回一个None,表示啥也没有:
>>> dict1.get(31)
'赞'
>>> dict1.get(32)
>>>
如果找不到数据的时候想返回一个指定的值,就需要用到get()方法到第二个参数设置默认返回值:
>>> dict1.get(32,'Python3v')
'Python3v'
>>>
如果判断一个键是否在字典中,那么可以使用成员资格操作符(in或not in)来判断:
>>> 31 in dict1
True
>>> 33 in dict1
False
>>> 33 not in dict1
True
在字典中检查键的成员资格比序列更高效,在数据规模比较大的时候,两者的差距会很明显(注:因为字典是采用哈希的方法一对一找到成员,而序列是采取迭代的方式逐个比对)。这里要注意一下查找的是键不是值,但是在序列中查找的是元素的值而不是元素的索引。
清空一个字典用clear()方法:
>>> dict1
{0: '赞', 1: '赞', 2: '赞', 3: '赞', 4: '赞', 5: '赞', 6: '赞', 7: '赞', 8: '赞', 9: '赞', 10: '赞', 11: '赞', 12: '赞', 13: '赞', 14: '赞', 15: '赞', 16: '赞', 17: '赞', 18: '赞', 19: '赞', 20: '赞', 21: '赞', 22: '赞', 23: '赞', 24: '赞', 25: '赞', 26: '赞', 27: '赞', 28: '赞', 29: '赞', 30: '赞', 31: '赞'}
>>> dict1.clear()
>>> dict1
{}
有的会直接给字典重新赋一个空值,这样做有一个弊端。看一下例子:
>>> dict1 = {'name': 'Python3v'}
>>> dict2 = dict1
>>> dict2
{'name': 'Python3v'}
>>> dict1 = {}
>>> dict1
{}
>>> dict2
{'name': 'Python3v'}
dict1和dict2同指定一个字典,然后试图通过重新指向一个空字典,来达到清空的目的,然而发现字典并没有被真正清空,只是dict1指向来一个新的空字典而已。所以这种做法会留下隐患的。
推荐的是使用clear()方法:
>>> dict1 = {'name': 'Python3v'}
>>> dict2 = dict1
>>> dict2
{'name': 'Python3v'}
>>> dict1.clear()
>>> dict1
{}
>>> dict2
{}
1.2.4 copy()
copy()方法是复制字典
>>> dict1 = {'name': 'Python3v'}
>>> dict2 = dict1.copy()
>>> id(dict1)
140362688825608
>>> id(dict2)
140362688824136
>>> dict1[0] = 'Hello'
>>> dict1
{0: 'Hello', 'name': 'Python3v'}
>>> dict2
{'name': 'Python3v'}
1.2.5 pop()和popitem()
pop()方法是给定键弹出对应的值,popitem()是弹出一个项。看一下例子:
>>> dict1 = {1:'one',2:'two',3:'three',4:'four'}
>>> dict1.pop(2)
'two'
>>> dict1
{1: 'one', 3: 'three', 4: 'four'}
>>> dict1.popitem()
(1, 'one')
>>> dict1
{3: 'three', 4: 'four'}
setdefault()方法和get()方法有点相似,但是setdefault()在字典中找不到相应的键时会自动添加。
>>> dict1 = {1:'one',2:'two',3:'three'}
>>> dict1.setdefault(3)
'three'
>>> dict1.setdefault(4)
>>> dict1
{1: 'one', 2: 'two', 3: 'three', 4: None}
1.2.6 update()
update()方法是用来更新字典:
>>> dict1 = {'Linux':'Centos','Ruby':'Ruby2.5','Go':'Go3.2'}
>>> dict1.update(Python='Python3v')
>>> dict1
{'Go': 'Go3.2', 'Ruby': 'Ruby2.5', 'Linux': 'Centos', 'Python': 'Python3v'}
Python还有两一种收集方式,就是用两个星号(**)表示,两个星号的收集参数表示为将参数们打包成字典的形势,收集参数其实有两种打包方式:一种是以元组的形势打包,另一种则是以字典的形式打包。
>>> def test(**params):
... print('有%d个参数'% len(params))
... print('它们分别是:', params)
...
>>> test(a=1,b=2,c=3,d=4)
有4个参数
它们分别是: {'a': 1, 'b': 2, 'd': 4, 'c': 3}
函数部分后面在说,先看参数,当参数带有两个星号(**)时,传递给函数的任意个key=value实参会被打包进一个字典中,那么打包就有解包,来一下例子:
>>> dict1 = {'Linux':'Centos','Ruby':'Ruby2.5','Go':'Go3.2'}
>>> test(**dict1)
有3个参数
它们分别是: {'Go': 'Go3.2', 'Ruby': 'Ruby2.5', 'Linux': 'Centos'}
2 集合:你就是我世界里的唯一
Python的字典时对数学中映射概念支持的直接体现,而集合呢?下面看一下代码:
>>> num1 = {}
>>> type(num1)
<class 'dict'>
>>> num2= {1,2,3,4,5}
>>> type(num2)
<class 'set'>
在Python3里,如果用大括号括起来一堆数字但是没有体现映射关系,那么Python就认为这是集合。
集合在Python中几乎起到的所有作用就是两个字:唯一。举个例子:
>>> num1 = {1,2,3,2,3,4,3,4,5,4,5,6}
>>> num1
{1, 2, 3, 4, 5, 6}
可以看到集合就会把重复的数据清理掉,但是集合也是无序的,也就是说你不能试图去索引集合中的某一个元素。
>>> num[1]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'num' is not defined
2.1 创建集合
创建集合有两种方法:一种是直接把一堆元素用大括号({})括起来;另一种是用set().
>>> set1 = {'Python3v','Python','Linux'}
>>> set2 = set(['Python3v','Python','Linux'])
>>> set1 == set2
True
如果在没学习集合之前去除列表[1,2,3,4,2,3,4]中重复的元素,如果还没有学习过集合可以这样写:
>>> list1 = [1,2,3,4,2,3,4]
>>> temp = list1[:]
>>> list1.clear()
>>> for i in temp:
... if i not in list1:
... list1.append(i)
...
>>> list1
[1, 2, 3, 4]
但是学过集合呢?可以这样:
>>> list1 = [1,2,3,4,2,3,4,0]
>>> list1 = list(set(list1))
>>> list1
[0, 1, 2, 3, 4]
由于set()创造了集合,而内部是无序的。所以再调用的list()将无序的集合转换成列表就不能保证原来的列表的顺序了(这里Python好心办坏事,把0放到了前面),所以如果关注列表中元素的前后顺序问题,使用set()函数时就要考虑一下了。
2.2 访问集合
由于集合的元素是无序的,所以并不能像序列那样用下标来进行访问,但是可以使用迭代把集合中的数据一个一个读取出来。
>>> set1 = {1,2,3,2,3,4,5,6,4,5,6,0}
>>> for i in set1:
... print(i, end='')
...
0123456
也可以使用in和not in判断一个元素是否在集合中已经存在:
>>> 0 in set1
True
>>> 9 in set1
False
>>> 10 not in set1
True
使用add()方法为集合添加元素,使用remover()方法可以删除集合中已知的元素:
>>> set1.add(9)
>>> set1
{0, 1, 2, 3, 4, 5, 6, 9}
>>> set1.remove(0)
>>> set1
{1, 2, 3, 4, 5, 6, 9}
2.3 不可变集合
为了使集合的数据具有稳定性,像元组一样不能随意地增加或删除集合中的元素,那么久可以定义一个不可变集合,使用frozenset()函数,就是把元素给frozen(冰冻)起来:
>>> set1 = frozenset({1,2,3,4,5})
>>> set1.add(6)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
评论列表