人脸检测江湖的那些事儿
图片:teguhjatipras / CC0
 人类的悲欢并不相通。
人类的悲欢并不相通。
题外话
这是 Face++ Detection Team(R4D)第 3 篇知乎专栏。如果说该专栏的定位是双向交流,一个比较贴切的词可能是「窗口」:一方面,我们希望从论文的生产、研究员的成长乃至公司的文化氛围等多方面被了解,被认识,被熟悉,希望携手共同见证最优检测算法的研究、创新与落地,突破认知边界,实现降本增效,为客户和社会创造最大价值;另一方面,我们也希望了解读者的想法,增加与读者的互动,形成双向反馈的正向沟通机制。R4D 后续也会组织线下活动,加大加深彼此交流。如果你感兴趣,或者想加入,欢迎联系 Face++ Detection Team 负责人俞刚 ([email protected])。
本次分享的主题是人脸检测(Face Detection),分享者是旷视科技王剑锋,来自 Face++ Detection 组。通过这篇文章,可以一窥旷视近两年在该方向的工作与思考,并希望为计算机视觉社区带来启发,进一步推动人脸检测技术的研究与落地。人脸检测是人脸识别的第一站,旷视的努力主要体现在紧紧围绕人脸检测领域顽固而核心的问题展开,攻坚克难,功夫花在刀刃上,比如人脸尺度的变动及遮挡等,实现速度与精度的双重涨点。
前言
人脸检测的目的是,给定任意图像,返回其中每张人脸的边界框(Bounding Box)坐标,实际操作上它对通用物体检测(General Object Detection)有较多借鉴,是通用物体检测技术的聚焦和细分。由于人脸检测是所有人脸分析算法的前置任务,诸如人脸对齐、人脸建模、人脸识别、人脸验证 / 认证、头部姿态跟踪、面部表情跟踪 / 识别、性别 / 年龄识别等等技术皆以人脸检测为先导,它的好坏直接影响着人脸分析的技术走向和落地,因而在学术界和工业界引起广泛的重视和投入。
如今,随着深度学习普及,人脸检测与通用物体检测已相差无几,作为二分类任务,其难度也低于通用物体检测,因此现阶段人脸检测研究更需走差异化路线,从实际应用中汲取营养。
尺度变化是人脸检测不同于通用物体检测的一大问题。通用物体的尺度变化范围一般在十几倍之内;与之相比,人脸的尺度变化范围由于摄像头不断升级,在 4K 甚至更高分辨率场景中可达数十倍甚至上百倍。面对这一问题,[1, 2] 给出的答案是寻找最优尺度多次采样原图,其本质是优化图像金字塔(Image Pyramid);[3, 4] 则利用不同深度的特征图适应不同尺度的人脸,其本质是优化特征金子塔(Feature Pyramid);而旷视自主研创的 SFace 方法试着从完全不同的角度切入这一问题。这是本文第一部分。
和尺度变化一样,遮挡也是人脸检测面临的常见挑战之一。实际场景中的眼镜、口罩、衣帽、头盔、首饰以及肢体等皆会遮挡人脸,拉低人脸检测的精度。对此,[5, 6] 尝试提升神经网络适应遮挡情况的能力,[7] 则将问题转化为遮挡与非遮挡人脸在向量空间中的距离这一度量学习问题。此外,很多深度学习方法训练时辅用的数据增强技术也在一定程度上提高了网络对遮挡情形的鲁棒性;而旷视原创的全新算法 FAN 也是针对人脸遮挡问题而提出。这是本文第二部分。
如上所述,人脸检测是人脸关键点、人脸识别等的前置任务,人脸检测框质量直接影响着整条 Pipeline 的表现,常见人脸检测数据集的评测指标对边界框质量缺乏关注;2018 WIDER Challenge Face Detection 首次采用相同于 MS COCO 的评测方式,表明这一状况已有大幅改善;本文第三部分则将介绍这次比赛夺冠的一些诀窍。
尺度变化: SFace
SFace: An Efficient Network for Face Detection in Large Scale Variations
目前的人脸检测方法仍无法很好地应对大范围尺度变化,基于图像金字塔的方法理论上可覆盖所有尺度,但必须多次采样原图,导致大量重复计算;而基于特征金字塔的方法,特征层数不宜加过多,从而限制了模型处理尺度范围的上限。是否存在一种方法,图像只通过模型一次,同时又覆盖到足够大的尺度范围呢?
目前,单步检测方法大致可分为两类:1)Anchor-based 方法,如 SSD[8]、RetinaNet[9] 等;2)Anchor-free 方法,如 DenseBox[10]、UnitBox[11] 等。Anchor-based 方法处理的尺度范围虽小,但更精准;Anchor-free 方法覆盖的尺度范围较大,但检测微小尺度的能力低下。一个非常自然的想法就是,两种方法可以融合进一个模型吗?理想很丰满,现实很骨感,Anchor-based 和 Anchor-free 方法的输出在定位方式和置信度得分方面差异显著,直接合并两个输出困难很大,具体原因如下:
其一,对于 Anchor-based 方法,ground truth IoU ≥ 0.5 的锚点将被视为正训练样本。可以发现,正负样本的定义与边界框回归结果无关,这就导致 Anchor-based 分支每个锚点输出的分类置信度实质上表示的是「锚点框住的区域是人脸」的置信度,而不是「网络预测的回归框内是人脸」的置信度。故而分类置信度很难评估网络实际的定位精度。对于在业务层将 Classfication Subnet 和 Regression Subnet 分开的网络,情况将变得更为严重。
其二,对于 Anchor-free 方法,网络训练方式类似于目标分割任务。输出的特征图以边界框中心为圆心,半径与边界框尺度成比例的椭圆区域被定义为正样本区域,特征图其它位置(像素)被视为背景。通过这种方式,Anchor-free 分支的分类置信度得分实质为「该像素落在人脸上」的置信度,而且该分类置信度与定位的准确度的关联同样很弱。
总而言之,Anchor-based 方法和 Anchor-free 方法的分类置信度都与回归定位精度关联甚微,其置信度得分也分别代表着不同的含义。因此通过分类结果直接合并两个分支输出的边界框是不合理的,并且可能导致检测性能的急剧下降。
因此,可以将回归的边界框和 ground truth 边界框之间的 IoU 当作 Classfication Subnet 的 ground truth,这正是 SFace 所做的事情。
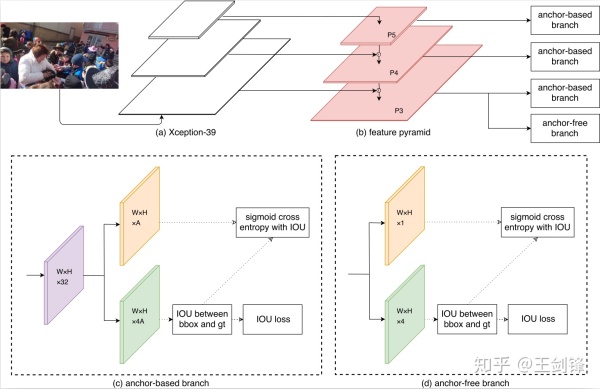
具体而言,SFace 设计了 Anchor-based 和 Anchor-free 两个分支,前者基于 RetinaNet,后者基于 UnitBox;两个分支都在训练第一步通过 Regression Subnet 生成边界框;接着计算边界框和 ground truth 边界框之间的 IoU;(Anchor-based 分支的)锚点和(Anchor-free 分支的)像素中 IoU ≥ 0.5 的结果将视为 Classfication Subnet 的正样本,其它则视为负样本,Classfication Loss 采用 Focal Loss。我们还尝试过直接回归 IoU,然而实验结果表明,相较于采用 Sigmoid Cross Entropy 或 Focal Loss,直接回归 IoU 所得结果方差较大,实际效果欠佳。
Anchor-based 分支和 Anchor-free 分支都使用 IoU Loss 做为 Regression Loss。这种调整有助于统一两个分支的输出方式,优化组合结果。通过以上修正,两个分支的分类子网络的实质含义得到统一,分类置信度的分布得到一定程度的弥合,从而 SFace 可有效融合两个分支的结果。
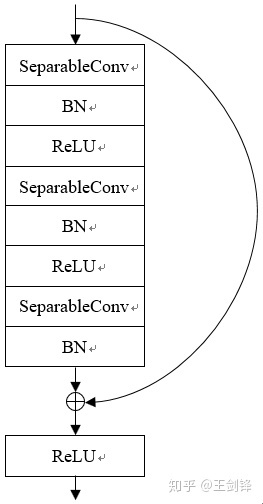
此外,SFace 必须运行很快才有实际意义,否则大可以选择做图像金字塔。为此,基于 Xception,SFace 采用了一个 FLOPs 仅有 39M 的 Backbone,称之为 Xception-39M,每个 Block 包括 3 个 SeparableConv 的 Residual Block。Xception-39M 运算量非常小,感受野却高达 1600+,十分适合处理更高分辨率图像。
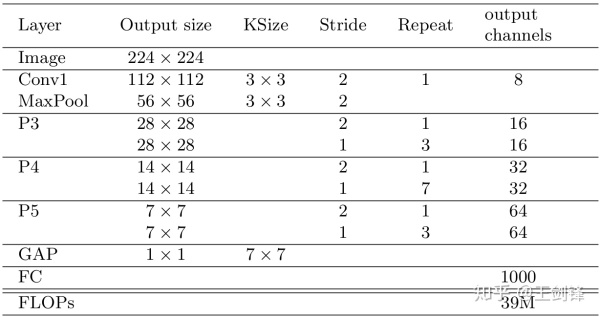
SFace Backbone 理论计算量只有下表中部分方法的 1/200(这些方法多采用 VGG-16、ResNet-101 等作为 Backbone),且都采用多尺度测试;而 SFace 测试全部在单一尺度下进行。事实上,SFace 的设计初衷正是只在一个尺度下测试即可覆盖更大范围的尺度变化。
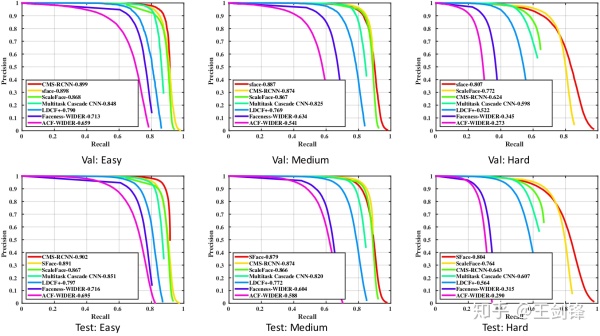
消融实验证明直接融合 Anchor-based 与 Anchor-free 方法不可行,而 SFace 提出的融合方法是有效的。Anchor-free 分支覆盖了绝大多数尺度(easy set 和 medium set),而 Anchor-based 分支提升了微小人脸(hard set)的检测能力。
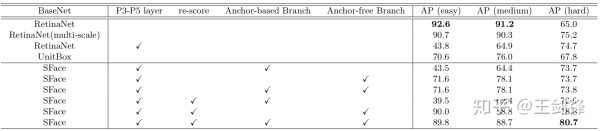
4K 分辨率下,SFace 运行速度上接近实时,据知这是首个在 4K 分辨率下 WIDER Face hard AP 高于 75 的实时人脸检测方法。

遮挡:FAN
Face Attention Network: An Effective Face Detector for the Occluded Faces
我们可以从另一个角度考虑遮挡问题。一个物体在清晰可见、无遮挡之时,其特征图对应区域的响应值较高;如果物体有(部分)遮挡,理想情况应是只有遮挡区域响应值下降,其余部分不受影响;但实际情况却是整个物体所在区域的响应值都会降低,进而导致模型 Recall 下降。
解决这个问题大概有两种思路:1)尽可能保持住未遮挡区域的响应值,2)把无遮挡区域降低的响应值弥补回来;前者较难,后者则相对容易。一个简单的做法是让检测器学习一个 Spatial-wise Attention,它应在无遮挡区域有更高的响应,然后借助它以某种方式增强原始的特征图。
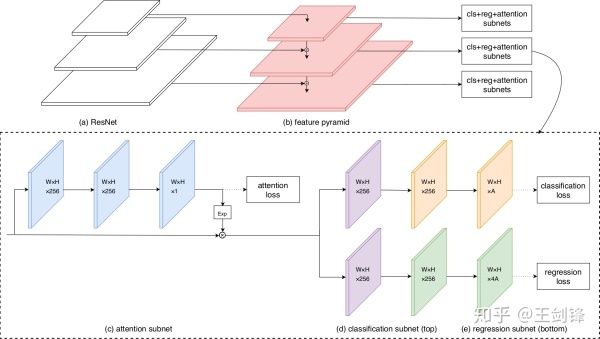
那么,如何设计这个 Spatial-wise Attention。最简单考虑,它应当是一个 Segmentation Mask 或者 Saliency Map。基于 RetinaNet,FAN 选择增加一个 Segmentation 分支,对于学到的 Score Map,做一个 exp 把取值范围从 [0, 1] 放缩到[1, e],然后乘以原有的特征图。为简单起见,Segmentation 分支只是叠加 2 个 Conv3x3,Loss 采用 Sigmoid Cross Entropy。
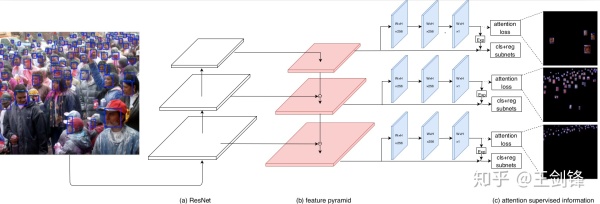
这里将面对的一个问题是,Segmentation 分支的 ground truth 是什么,毕竟不存在精细的 Pixel-level 标注。由于人脸图像近似椭圆,一个先验信息是边界框区域内几乎被人脸填满,背景区域很小;常见的遮挡也不会改变「人脸占据边界框绝大部分区域」这一先验。基于这一先验可以直接输出一个以边界框矩形区域为正样本、其余区域为负样本的 Mask,并将其视为一个「有 Noise 的 Segmentation Label」作为实际网络的 ground truth。我们也尝试根据该矩形截取一个椭圆作为 Mask,但实验结果表明基本没有区别。
这样的 ground truth 真能达到效果吗?通过可视化已学到的 Attention Map,发现它确实可以规避开部分遮挡区域,比如一个人拿着话筒讲话,Attention Map 会高亮人脸区域,绕开话筒区域。我们相信,如果采用更复杂的手段去清洗 Segmentation Label,实际效果将有更多提高。
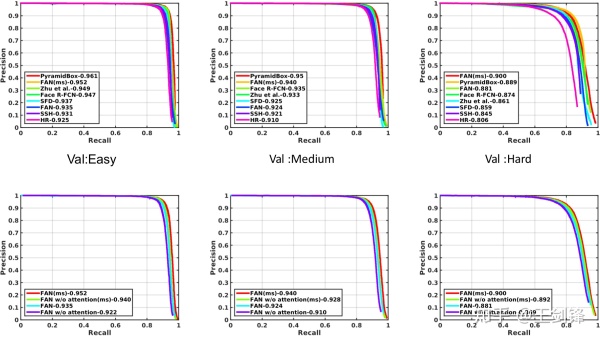
FAN 在 WIDER Face 上曾经保持了半年的 state-of-the-arts。由于仅仅验证方法的可行性,FAN 没有叠加任何 trick,只在原始的 RetinaNet 上调整锚点框,增加我们的 Spatial Attention,因此 FAN 还有很大的上升空间。
定位精度:2018 WIDER Challenge Face Detection
第三部分介绍一下旷视科技夺魁 WIDER Face and Pedestrian Challenge 2018 上的解决方案。2018 WIDER Challenge 有 3 个 track,旷视参战了其中的 Face Detection。更多信息请参见:ECCV 2018 | 旷视科技夺获人工智能顶赛 Wider Challenge 人脸检测冠军。

Face Detection 使用 WIDER Face 数据集原始图像,但是 Label 做了一定修正。据我们统计,Label 数量稍多于原数据集,导致在不对模型做任何更改的情况下,使用新 Label 也会比原 Label 涨点(更新:目前 WIDER Face 官网上已经用 WIDER Challenge Label 覆盖原 Label,不再存在此问题)。此外,WIDER Challenge 数据集不同于 WIDER Face 数据集的是,使用了相同于 MS COCO 的 Metrics,这意味着对模型的回归能力提出了更高的要求。
旷视夺冠的方法仍然基于 RetinaNet。通过对比常见 Backbone,我们给出了以下表格的结果。可以发现,更强的 Backbone 并不意味着更好的 Detection 能力。一些 Backbone 分类能力更强,但是提供的特征或者分层特征并不够好;感受野等对 Detection 至关重要的因素也不合适;对于二分类问题而言也存在过拟合现象。由于实验周期等原因,我们最后简单选择了 ResNet-50 和 DenseNet-121 继续后面的实验。需要声明的是,它们在很多情况下都不是最优 Backbone,我们有必要思考何种 Backbone 提取的特征最适合做检测。
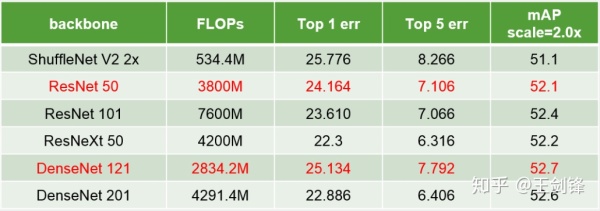
我们在 Backbone 上应用了 GAP trick,这在上篇知乎专栏(ycszen:语义分割江湖的那些事儿——从旷视说起)有所介绍。该 trick 同样适用于 Detection。我们还使用了 Deformable Conv,但其贡献主要是扩大 ResNet 原本不高的感受野。
对于 Head 部分,我们首先将 Smooth L1 Loss 换成 IoU Loss,这是为照顾数据中占比较多的小脸,但实际分析一下可以发现,在锚点框合适的情况下,IoU Loss 的提升会很微小。我们对 Head 的主要改动是做一个简单的 Cascade。Cascade R-CNN[12] 是最早通过做 Cascade 提升模型 Regression 能力的方法,我们希望将其移植到单步检测器上。
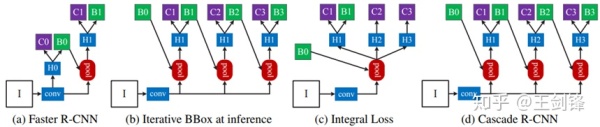
可以发现,具体做法部分借鉴了 SFace,即把前一个 Stage 的预训练边界框与 ground truth 边界框之间的 IoU 作为下一个 Stage 的 Classification Label;随着 IoU 逐渐提升,每个 Stage 的 IoU threshold 也逐渐增大,这与 Cascade R-CNN 很类似。
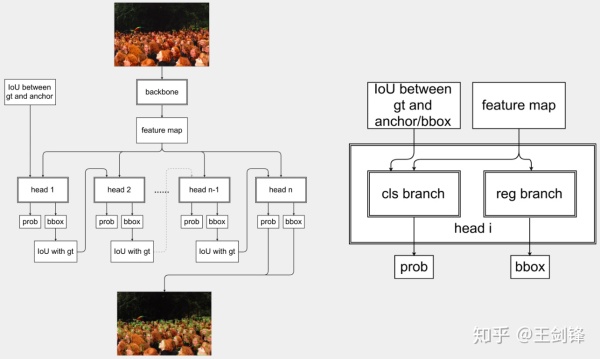
这个 Cascade 方案不难想到,也简单易行,但是的确涨点,Inference 时也只需保留最后一个 Stage,不会增加 Inference 成本;这个方案也有自己的问题,最大的是每个 Stage 在共用同一个特征图,也共用不变的 anchor,对此已有一些相关论文提出改进,如[13, 14, 15]。
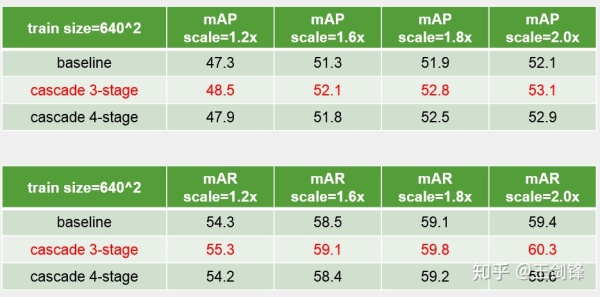
此外,我们还在 Data Augmentation、Ensemble 等方面做了改进,由于比较 trivial,这里不再赘述。我们曾在 ECCV 2018 Workshop 展示过该方案,更多内容请查阅 slides:
WIDER Face Challenge workshop.pptx
作者简介
王剑锋,北京航空航天大学软件学院硕士,旷视科技研究院算法研究员,研究方向人脸检测、通用物体检测等;人脸检测算法 SFace 和 FAN 一作;2018 年参加计算机视觉顶会 ECCV 挑战赛 WIDER Challenge 获得人脸检测(Face Detection)冠军。
参考文献:
[1] Hao Z, Liu Y, Qin H, et al. Scale-Aware Face Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6186-6195.
[2] Liu Y, Li H, Yan J, et al. Recurrent Scale Approximation for Object Detection in CNN[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 571-579.
[3] Yang S, Xiong Y, Loy C C, et al. Face Detection through Scale-Friendly Deep Convolutional Networks[J]. arXiv preprint arXiv:1706.02863, 2017.
[4] Zhu C, Zheng Y, Luu K, et al. CMS-RCNN: contextual multi-scale region-based CNN for unconstrained face detection[M]//Deep Learning for Biometrics. Springer, Cham, 2017: 57-79.
[5] Opitz M, Waltner G, Poier G, et al. Grid loss: Detecting occluded faces[C]//European conference on computer vision. Springer, Cham, 2016: 386-402.
[6] Chen Y, Song L, He R. Adversarial Occlusion-aware Face Detection[J]. arXiv preprint arXiv:1709.05188, 2017.
[7] Ge S, Li J, Ye Q, et al. Detecting Masked Faces in the Wild With LLE-CNNs[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2682-2690.
[8] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[9] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2980-2988.
[10] Huang L, Yang Y, Deng Y, et al. Densebox: Unifying landmark localization with end to end object detection[J]. arXiv preprint arXiv:1509.04874, 2015.
[11] Yu J, Jiang Y, Wang Z, et al. Unitbox: An advanced object detection network[C]//Proceedings of the 2016 ACM on Multimedia Conference. ACM, 2016: 516-520.
[12] Cai Z, Vasconcelos N. Cascade r-cnn: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6154-6162.
[13] Chen X, Yu J, Kong S, et al. Towards Real-Time Accurate Object Detection in Both Images and Videos Based on Dual Refinement[J]. arXiv preprint arXiv:1807.08638, 2018.
[14] Wang J, Chen K, Yang S, et al. Region proposal by guided anchoring[J]. arXiv preprint arXiv:1901.03278, 2019.
[15] Kong T, Sun F, Liu H, et al. Consistent Optimization for Single-Shot Object Detection[J]. arXiv preprint arXiv:1901.06563, 2019.