同是算法工程师,年薪 20 万和 100 万的差别在哪?
图片:《现代生活的秘密规则》
做算法工程师是什么样的工作体验?
 数据挖掘 / 曾用ID:阿萨姆
数据挖掘 / 曾用ID:阿萨姆
体验有很多,个中心酸不足为外人道也。
1. 算法工程师与项目经理间的矛盾
因为机器学习发展太快,整个行业还没有储备足够的项目经理。因此导致的结果有二:
- 工程师转型做项目经理:优点是了解技术,但往往缺乏商业洞察力,抓不到产品方向
- 非算法背景出身的项目经理:以为算法和模型可以解决所有问题,对于项目的实际困难缺乏应有的了解与合理的评估
项目经理需要理解:算法不是万能的,机器学习模型不总奏效,有一定的概率失败。而从传统行业的项目经理角度来看,很难理解为什么一个“代码项目”会失败,他们以为只要花时间按部就班的实施即可。然而任何数据导向的项目都有可能会失败,原因有很多:
- 数据量和数据质量有问题
- 缺乏合适的算法
- 模型训练需要过高的代价,计算力不够
- 因为各种 bug 而导致的无法收敛
2. 量化模型的效果与个人发展
另一个使得算法工程师落入尴尬境地的问题是:很难量化模型为公司带来的直接收益。换句话说,对于算法工程师制定 KPI 是比较难的一件事,而算法工程师很难因此获得公司老板的嘉奖。
换句话说,很多时候往往很难说“模型 A 为公司带来了 X 新客户,创造了 y 价值”。因此对于工程师来说,更加重要的是如何“包装”自己的模型,至少要宣传自己的模型是有价值的,不然很难得到升职加薪。
抬头看天,低头看路。要提防钻到模型中,而忽视了个人发展。钻研技术与获得匹配的嘉奖是合理的,“工匠精神”应该被嘉奖,而不该仅是默默奉献为人抬轿,甘愿做螺丝钉。
3. 实用性与性能间的取舍
做机器学习的人都绕不开解释模型,而很多时候一个模型是否能被管理层接受完全取决于他们对于模型的信心。人是主观的,很多时候模型效果再好不能解释也会被毙掉。
因此另一个做算法的体验就是,一定要能在性能与解释度上找平衡,不能一味追求模型性能良好。在很多情况下,决策者愿意牺牲掉一定的性能而换取更高的可解释度。因此直到今天,很多算法岗都还在用逻辑回归。当然,这个是分领域的,做视觉和语言的一般走的快一些,而传统行业的算法更加保守。
所以作为一个工程师,应从全局角度出发,防止沉迷于性能,而忽视了实用性。另一个异曲同工的考量是模型精度与运算速度的取舍。举个简单例子,融合多个模型可以达到高精度模型,但代价是运算开销成倍上升。在很多精度第一的情况下,那么我们可以接受这样的代价。当运算开销更重要时,我们应该优先选择简单但性能尚可的模型。因此要灵活,不要追寻定式。
4. 科研创新与应用 -“落后的工业界”
不少答主也提到了学界前沿算法与实际应用间的断层,即很多前沿算法并不实用。那是因为工业界比学术界更加落后?还是因为学术界都是“骗经费”的呢?
都不是,单纯是因为研究成果商业化周期的滞后性。学术界的研究成果,在能够商业化前还有很长的路要走,如下图所示一般要经历多个步骤并且不同的环节之间都有“门槛”,很多研究成果往往走不到商业化那一步。而能够成功商业化的研究成功往往都是历经考验,被大家认为真实有效,并可以为社会提供价值的。检验这个过程一般有漫长的周期,短则几个月,长则很多年,这个周期给了很多人错觉工业界很落后。其实不然,工业界只是更加保守。和有政府拨款的研究机构不同,企业的主要任务是盈利而不是探索科技的边界,同时还得考虑到人力成本、产品痛点等复杂的因素。学术界成熟的算法和成果,只要能在应用领域上落地,很快就会被商业化走入我们的生活。换句话说,学术界的成功经过自己的内部筛选和沉淀,能够存活下来的就会进一步被商业化。
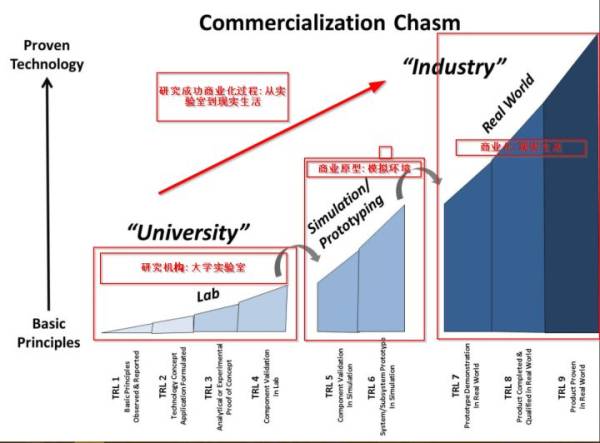
可能短时间内某个领域学术界走的快一些或者工业界走的快一些,但总体来讲很少有极端滞后性。作为一个已经身在工业界的人,我们也紧跟学术界的潮流,尽量了解下一个可能大热的技术是什么。很多公司还会安排员工去参加学术会议,争取将可靠的技术尽快商业化落地。
从算法工程师的角度来看,从成本控制的角度还是优先尝试成熟的算法。在缺乏成熟算法的情况下,也不妨“追逐一下”学界热点。如果更进一步,算法工程师很适合开展研究,反哺学界。现在不少前沿成果都是企业的,如 Google,因为其科研投入和天生的数据优势。更多相关讨论可以参考[2]。
5. 数据提取、整合与清理 - 全栈工程师?
另一个广为人诟病的就是“建模五分钟,清理数据两小时”。更加极端的是因为公司的定位,导致算法工程师不仅仅需要建模,还需要包产一条龙,因此对于算法工程师的期待越来越高:
- 熟悉各种数据库以及分布式计算:方便从多个平台收集数据
- 熟悉各种数据清理操作以及算法模型的数学原理
- 了解可视化:可以展示模型成果等
- 接触过模型部署上线:拥有架构经验和部署经验
当然,这个和公司规模有关。算法工程师在大公司会被继续细分,做到专精。根据公司规模,对算法工程师的技能期望有一定的差异化,一个粗略的分类见下图。
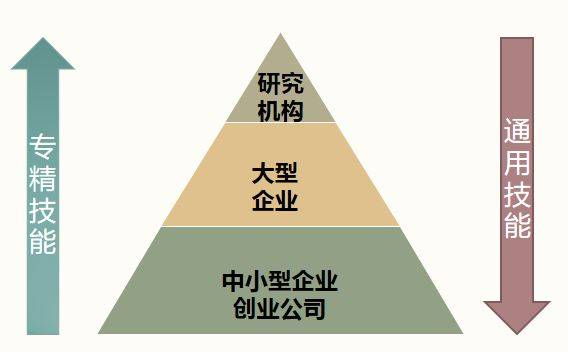
大公司一般更需要专精岗位,一般要求你在特定方向出类拔萃,可以适当放宽其他要求。比如可能要求你深入理解机器视觉,但不要求你精通 Spark 或者自然语言处理。
而中小型公司因为资金和能力的限制,更需要通用型人才,职位一般也分得没那么细。正所谓“我是革命一块砖,哪里需要往哪搬”。在中小型企业,公司希望机器学习工程师可以独挑大梁,完成从数据收集、清理、建模、调整、到部署上线,甚至维护和更新的一系列工作。因此在大部分中小型公司的机器学习工程师也做了全栈的工作,捎带着把网站做了的也不是没有...
6. 成为一个有价值的算法工程师 - 1+1>2
虽然掌握每一个技能似乎都不复杂,但机器学习工程师的精髓之一就在于整合,即掌握以上所有的操作。当你可以把一系列技能掌握时,你一个人就是一支军队。更为重要的是,作为一个智力密集的岗位,从业者的质量比数量重要,一个厉害的算法大牛比一百个新手工程师更有意义。
给出一个简单例子以供参考,比如你在一家互联网公司想做一个信用卡欺诈预测模型,希望可以实时检测信用卡盗刷。基本的流程:
- 了解可使用的数据范围。比如你们有客户的基本信息,消费的信息(地点、时间、金额),消费场所的信息(是否是欺诈高发行业)。
- 收集和整合一切可用的历史信息,对数据进行必要的清洗。
- 使用可视化技术对数据进行初步分析。可视化可以在建模前帮助你节省大量的时间。
- 考虑要使用的模型和建模。以这个问题为例,如果我们把盗刷考虑为独立事件,那么可以简单的用普通分类器,如逻辑回归先建个模型试试。我们也可以把盗刷考虑为在时间轴上的事件,即你的消费历史会影响盗刷的可能性,那么就要考虑时间序列的上的相关性,可以使用循环网络或者把时间作为一个输入用于建模。
- 对模型进行回测和验证。在正式交付上线之前还需要进行大量的验证、微调、和性能优化。如果模型 A 需要 3 分钟做出预测准确率为 99%,而 B 模型只需要 3 秒但准确率是 98%,可能我们会选择模型 B。
- 将预测模型部署上线,并进行后期维护。随着收集到了新的数据,对模型进行线下更新训练并替换线上的模型。
不难看出,这一套流程中处处都要求极好的工程能力。一个人很容易可以拥有其中一部分技能,但很难同时掌握所有的技能。这解释了为什么高端的机器学习工程师“洛阳纸贵”,这也是检测你是否合格的一个标准。更多关于机器学习工程师技能的讨论,可以参考[3]。
7. 总结
不难看出,算法工程师所面临的挑战与机遇都来自于如何更好的对模型进行解释与包装。算法的目的是为企业创造价值,而不是单纯实现高精度。从职业角度出发,要在干活的同时学习如何“推销自己的工作”,防止受到不公平的对待与职业天花板。
从技术角度来看,追求专精与完整都有一定的优势,应根据个人情况灵活决定。专精型人才更适合大公司,而全栈型人才适合小公司。从某个角度来看,全栈型从业者的空间更为广阔,但不必为此追求面面俱到,容易狗熊掰棒子。
话说回来,尽管算法岗是当下最火热的求职方向,但降温总会发生,可以参考最近的讨论 [4]。因此不必执迷于岗位名称和现阶段的高待遇,做好自己最为重要。毕竟退潮终会来到,那时才方见谁是裸泳。
[1] Innovation Diffusion From University R&D