线性代数到底应该怎么学?
图片:geralt / CC0
 以诚为本,以朴修身,以勇求进,以毅建功
以诚为本,以朴修身,以勇求进,以毅建功
学习数学领域的一门科目的基础知识,无外乎两个目的,一个是在考试中取得好成绩,一个是在理解这些知识中,能在自己的研究中用到它。前一个目的很多回答已经概括的很好,这里不再赘述,所以呢,就结合自己从上课到学做研究的一些体会来服务于第二个目的读者。
一门学科入门,有两种方法,一种是从抽象到具体,一种是从具体到抽象。一开始就是一个很严密的抽象的定义,以及随之而来的一系列公式,对新手其实并不是很友好,而且也并不能帮助初学者仔细的思考这些公式和定义所蕴含的人类智慧。所以,我们就先从一些具体的案例出发,看看为啥线性代数里有那么多如“线性相关”似乎很无聊的概念以及围绕这些概念而来的理论吧。我们考虑三个比较基础的案例:线性方程组的求解;线段旋转与线性变换;以及高维数据降维与聚类。前两个是很经典的问题,最后一个是随着统计学特别是大数据时代到来变得在不同学科普遍出现的问题。让我们开始吧。
1.案例 1:线性方程组的求解
从小学开始,我们就开始学习如何求解下面的方程组(这个方程组里,

是未知数,其他为已知数,m 不一定等于 n):

方程组(1)简洁而又重要,因为许多理论以及简单的模型最后都可以归结为方程组(1)的求解。小学和初中学习的是加减消元法,高中后,算立体几何题,求法向量的时候,会用到行列式来求解这个方程组。上大学前,我们对于线性代数最基本的问题,线性方程组的求解,并不是很陌生。
不过,在读者欢天喜地的吭哧吭哧的求解方程组(1)的时候,或许想过,以及在具体的算例中碰到过如下问题:
- 方程组(1)与方程
似乎有联系,我们能否构造出更为一般的数学对象,把这种联系揭示出来,并且这些对象能有更广更深刻的理论以及应用?
- 如何对行列式做到 n 个变量的推广呢?与此相伴的问题时,行列式的究竟该如何定义呢?
- 方程组(1)什么时候有解,什么时候没有解,什么时候解释唯一的,什么时候解是不唯一的呢?
这三个问题,正是一本标准的线性代数教材里的前几章的知识所致力于回答的问题。解决思路就是引入向量空间,以及矩阵,那么(1)式可以形式上的写作:

我们只要研究系数矩阵

以及增广矩阵

就好了。怎么研究呢,那些絮絮叨叨的线性相关的理论就是为此服务的。
如果我们考虑我们熟悉的实数域的情况,当系数矩阵是方阵时,我们将行列式视作空间

到数域

的映射,即:

如果我们根据一阶行列式,二阶行列式的公式,递归的定义行列式

可以证明(3)是唯一满足如下条件的映射:
1)将单位矩阵

映射为 1
2)

其中省略号的行向量都是一样的;
3) 如果矩阵
相邻的行向量相同,那么

用行列式,线性相关,基,秩这些概念,我们便可以建立起关于方程

的有解的判别条件,以及解的结构的定理 ,这些标准的教材里都有,就不再赘述了。值得注意的是,如果我们将这套理论,移植到可微函数组成的线性微分方程组,我们也可以构造类似的命题,这说明我们可以将 矩阵和向量做更为一般的推广。
2. 案例 2,线段旋转与线性变换
如果读者用过 PS 或者 PPT 的时候,会发现里面的那些形状其实都是用坐标描述的,于是我们便可以将其视作

的一个子空间。考虑一个简单的问题,我们需要对 PS 里位于坐标原点的一段线段逆时针旋转一定的角度,PS 是如何实现这个功能的呢?很简单,我们只需要对这段线段对应的向量进行坐标变换就好了。如果进行变换呢?如果我们将方程(2)视作将向量 x 变换为向量 b,那么我们可以把矩阵 A“视作”一个变换。那么我们只要用一个二阶矩阵来表示旋转变换就好了,这个二阶矩阵,可以是

旋转变换是更为称为线性变换的具体案例,而且不改变线段的长度(保持距离)。此外,我们可以想象,如果一个向量的方向与旋转的方向一致,那么旋转变换是不会改变其方向的(这个向量就是所谓特征向量)。
标准的线性代数教材的后半部分,很大程度上是对这个线段旋转问题的扩展。矩阵的特征值,对角化,以及二次型的理论就是上面这个线段旋转问题的进一步研究。此外,二次型的相关理论还可以帮助我们回答二次曲线和曲面分类的问题。具体可见任何一本标准的线性代数教材,例如丘维声的书,这里不再赘述。
3. 案例 3:高维数据降维与聚类
这个案例和笔者的专业非常相关了。本质上来说是数理统计与线性代数的交叉。
当前生物研究中有一个非常前沿的技术,叫做单细胞转录组测序。例如我们可以从人身上抽外周血,进行单细胞测序,这些测序数据在经过一系列的处理之后,最终会得到一个称之为表达矩阵的对象,其中每一行对应一个基因,每一列对应一个细胞,所以这个数据真的是一个矩阵。如果读者看过《工作细胞》的话,或许知道外周血里有许多不同类型的细胞,比如 T 细胞,B 细胞,这些细胞之所以是不同的,真的是因为他们形态和功能特异。那么我们会问,能否从这么多细胞的表达谱将不同的细胞类型找出来呢。当然是可以的。
假如我们测了 2700 个单细胞,人的参考基因组注释出了 30000 个基因的话,那么我们的表达矩阵应该是

的十分稀疏的矩阵。我们希望能在二维的坐标图中,尽可能的展示出细胞类型的信息,并且能区分出不同的细胞类型。转化为两个子问题,那就是,高维矩阵降维,以及高维数据聚类的问题 。这中间有许多巧妙的算法。在实践中,高维矩阵降维我们常用的是 PCA,t-SNE,UMAP 等算法,而聚类的话,我们会用层次聚类以及 Louvain Algorithm 之类的图聚类算法,对每个细胞对应的高维向量进行聚类;
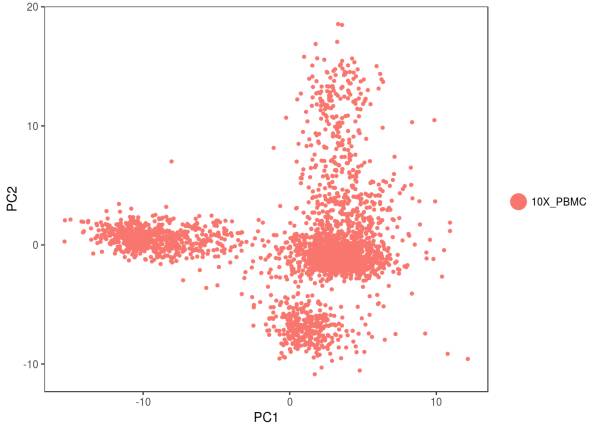
我们可以看看具体的步骤,这是 PCA 的结果,我们看到,细胞似乎能分为 4 个不同的大类 ;
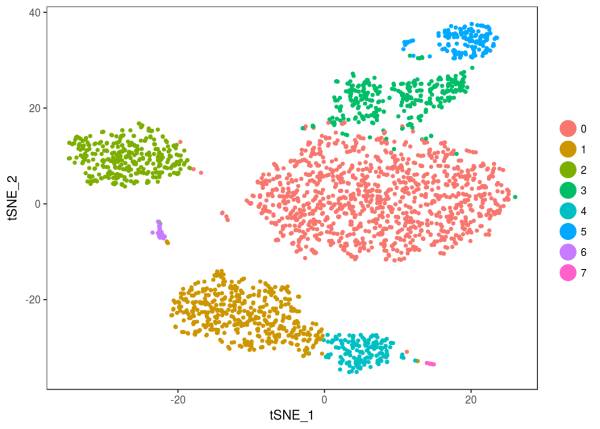
我们用非线性的降维方法 t-SNE,将这些细胞在二维的投影上分的更开,并且用 Louvain Algorithm,进行聚类 ,将聚类标签,用不同颜色展示出来;
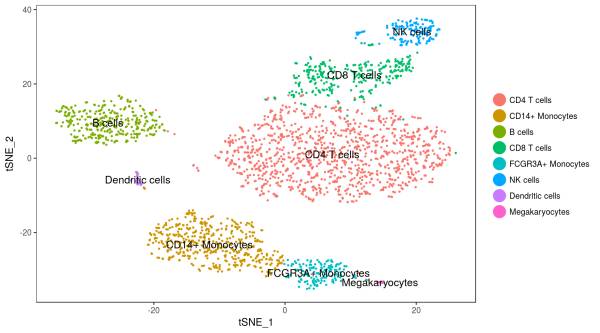
如果结合先验知识,查看每个类别对应细胞的差异表达基因,我们可以对每个类别进行注释,最终我们可以得到下面的这个结果:
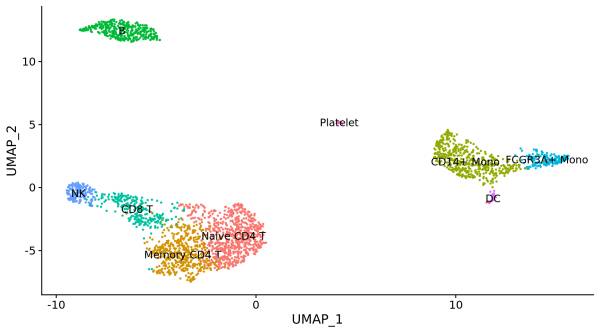
此外 ,还可以将 PCA 以及 t-SNE 纳入到流形学习的框架里,有学者提出了 UMAP 算法 ,能够更好的可视化,降维与聚类结果。
PCA,t-SNE,以及 UMAP 这些统计学习里的高级算法背后离不开矩阵分析和泛函分析(可以将其视为函数版本的线性代数)的相关理论,其策略就是定义度量空间以及范数,这里就不再做深入介绍了。只列出参考文献:
PCA 的介绍可见李航的《统计学习方法》;
t-SNE 原理以及代码实现见https://lvdmaaten.github.io/tsne/
UMAP 论文以及代码实现见https://github.com/lmcinnes/umap